Sprint Backlog 09
Sprint Mission
- Implement data management infrastructure.
Stories
Active
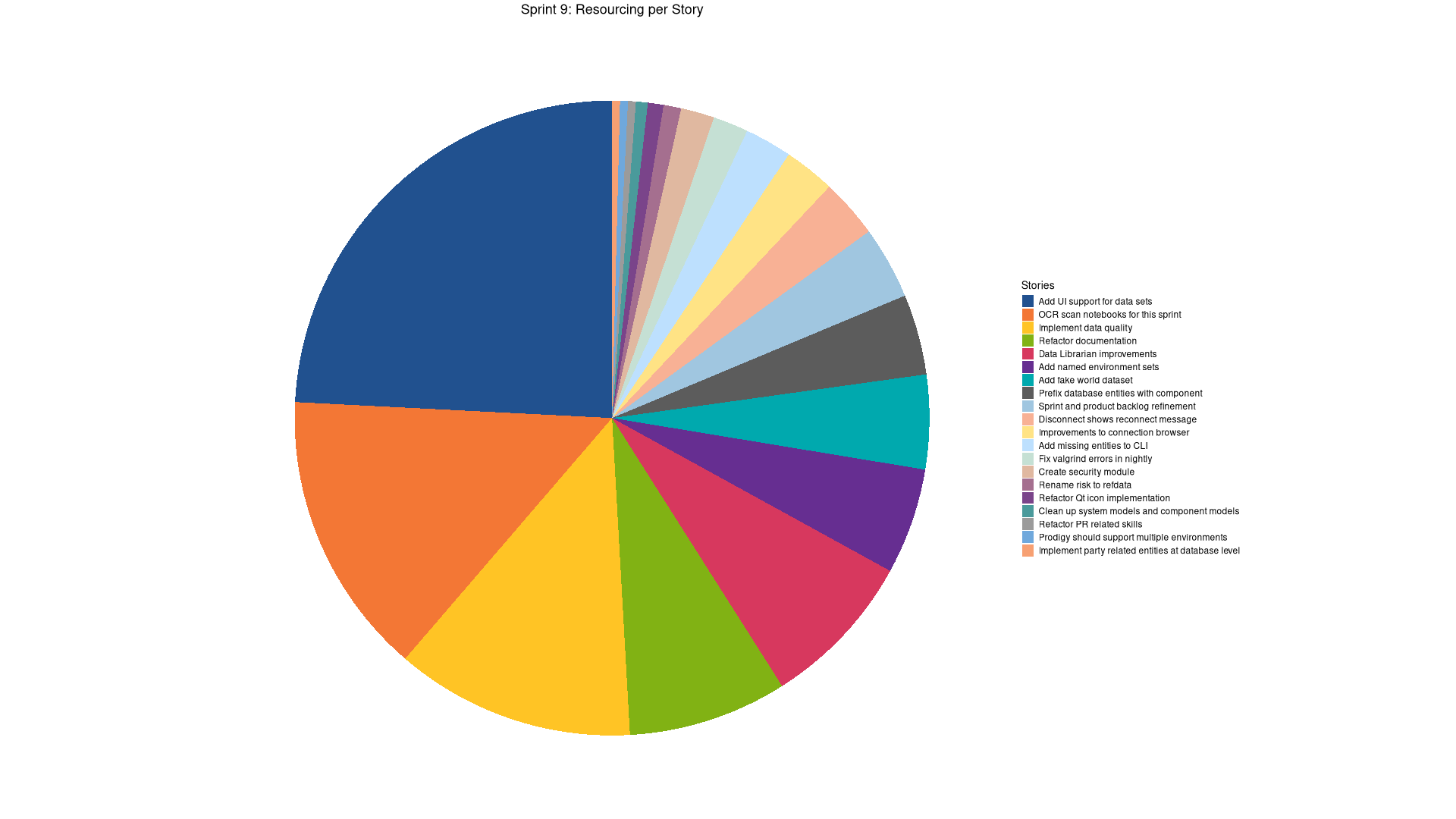
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 9:23 | 100.0 | |||
| Stories | 9:23 | 100.0 | |||
| Active | 9:23 | 100.0 | |||
| agile | Sprint and product backlog refinement | 0:45 | 8.0 | ||
| infra | OCR scan notebooks for this sprint | 1:38 | 17.4 | ||
| code | Refactor Qt icon implementation | 0:38 | 6.7 | ||
| code | Data Librarian improvements | 4:36 | 49.0 | ||
| code | Add fake world dataset | 1:46 | 18.8 |
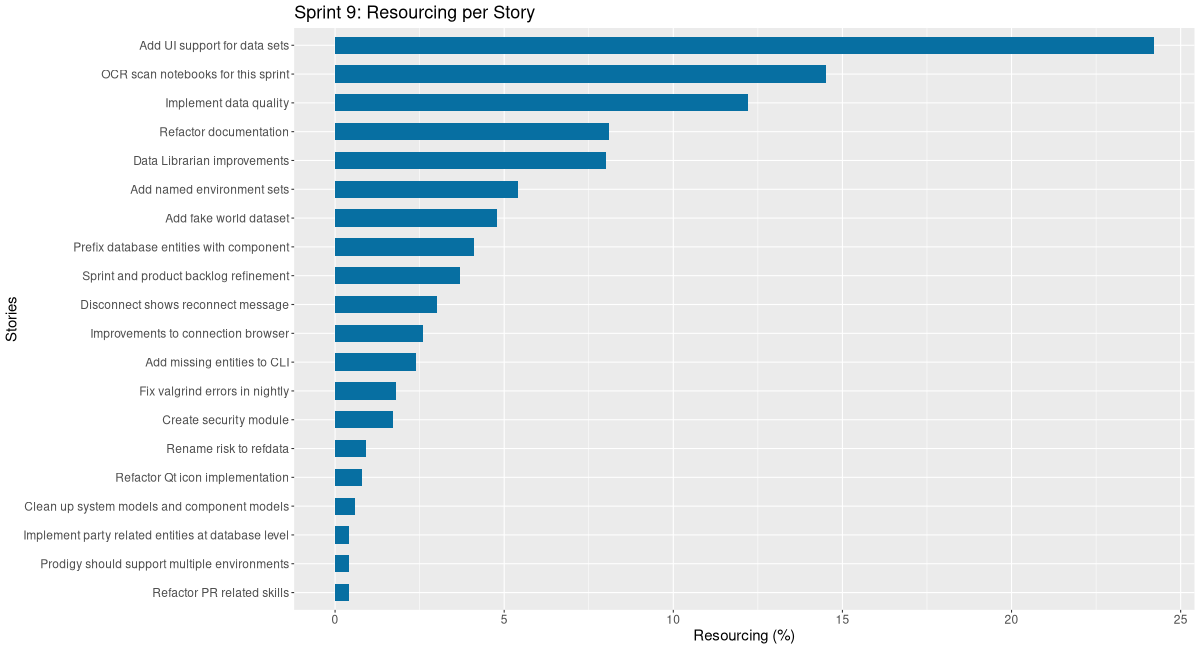
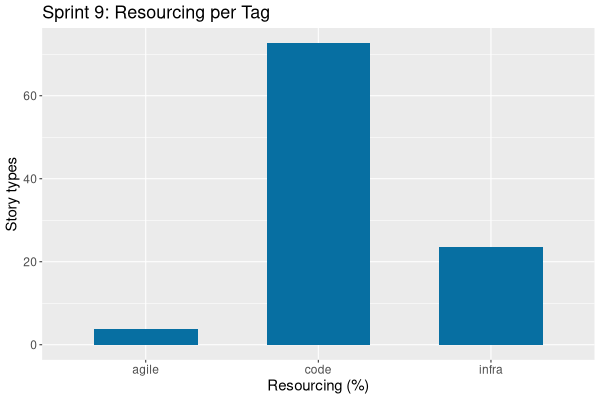
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 79:41 | 100.0 | |||
| Stories | 79:41 | 100.0 | |||
| Active | 79:41 | 100.0 | |||
| agile | Sprint and product backlog refinement | 2:56 | 3.7 | ||
| infra | OCR scan notebooks for this sprint | 11:31 | 14.5 | ||
| infra | Clean up system models and component models | 0:28 | 0.6 | ||
| code | Add missing entities to CLI | 1:55 | 2.4 | ||
| infra | Refactor PR related skills | 0:18 | 0.4 | ||
| code | Fix valgrind errors in nightly | 1:25 | 1.8 | ||
| code | Create security module | 1:23 | 1.7 | ||
| code | Prodigy should support multiple environments | 0:19 | 0.4 | ||
| code | Add named environment sets | 4:17 | 5.4 | ||
| code | Rename risk to refdata | 0:43 | 0.9 | ||
| code | Prefix database entities with component | 3:15 | 4.1 | ||
| code | Implement data quality | 9:42 | 12.2 | ||
| code | Improvements to connection browser | 2:05 | 2.6 | ||
| code | Disconnect shows reconnect message | 2:24 | 3.0 | ||
| code | Add UI support for data sets | 19:18 | 24.2 | ||
| code | Refactor Qt icon implementation | 0:38 | 0.8 | ||
| code | Data Librarian improvements | 6:24 | 8.0 | ||
| code | Implement party related entities at database level | 0:20 | 0.4 | ||
| infra | Refactor documentation | 6:29 | 8.1 | ||
| code | Add fake world dataset | 3:51 | 4.8 |
COMPLETED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
COMPLETED OCR scan notebooks for this sprint infra
We need to scan all of our finance notebooks so we can use them with AI. Each sprint will have a story similar to this until we scan and process them all.
COMPLETED Clean up system models and component models infra
These are out of sync with the latest refactorings.
This pull request significantly enhances the project's architectural documentation and internal tooling. It introduces a new skill to streamline the creation of component models, integrates several previously undocumented components into the system's architectural overview, and refines existing documentation practices to improve clarity and maintainability. The changes aim to provide a more comprehensive and accessible understanding of the system's structure and its various modules.
Highlights
- New Component Model Creator Skill: A new skill, 'component-model-creator', has been introduced to standardize the process of creating org-mode component documentation and PlantUML diagrams for architectural clarity.
- Expanded Component Documentation: Detailed component models and PlantUML diagrams have been created for 'ores.logging', 'ores.http', 'ores.http.server', and 'ores.wt', providing comprehensive insights into their architecture and functionality.
- Updated System Architecture: The main system model and architecture diagram ('ores.puml') have been updated to include the newly documented components and their interdependencies, offering a more complete system overview.
- Enhanced Skill Management Guidelines: The 'skill-manager' documentation now includes explicit guidelines for updating the skill dependencies diagram, ensuring consistency and ease of maintenance for skill relationships.
- Simplified Doxygen Main Page: The Doxygen main page has been streamlined, removing verbose content and instead linking directly to the external website documentation for system models and build instructions, improving navigation and reducing redundancy.
COMPLETED Add missing entities to CLI code
We have added entities but not updated the tool
- CLI commands
This pull request significantly expands the CLI's administrative capabilities by introducing comprehensive management commands for several key entities. Users can now list and delete roles, permissions, countries, change reasons, and change reason categories directly from the command line, enhancing operational efficiency and data control. The changes are implemented with flexible output formats and robust lookup mechanisms, providing a more complete and user-friendly experience for managing these system components.
Highlights:
- New CLI Entities: Added command-line interface support for five new entities: roles, permissions, countries, change reasons, and change reason categories.
- List Operations: Implemented 'list' operations for all new entities, supporting both JSON and table output formats.
- Delete Operations: Implemented 'delete' operations for all new entities, with support for lookup by UUID, code, or name depending on the entity type.
- Code Structure: Introduced new parser headers and implementations for each new entity, and integrated them into the existing application and parser logic.
- Parser refactoring
This pull request significantly improves the maintainability and conciseness of the CLI's entity parsing logic. By abstracting common patterns for entities that only support 'list' and 'delete' operations into a generic helper, it eliminates substantial boilerplate code and provides a standardized approach for handling such commands. This change is a direct response to previous code review feedback aimed at reducing duplication.
Highlights:
- New Generic Helper: Introduced a new simple_entity_config struct and handle_simple_entity_command helper function in parser_helpers to centralize common parsing logic.
- Refactoring of Entity Parsers: Refactored five existing entity parsers (roles, permissions, countries, change_reasons, change_reason_categories) to utilize the newly created generic helper.
- Code Reduction: Achieved a net reduction of approximately 314 lines of duplicated code across the refactored parsers, improving maintainability and conciseness.
COMPLETED Refactor PR related skills infra
This pull request streamlines and centralizes the Pull Request (PR) management process by renaming and significantly expanding the 'pr-summary' skill into a comprehensive 'pr-manager'. This change consolidates the entire PR lifecycle, from initial draft creation and CI integration to final merging, into a single, reusable skill. By doing so, it eliminates redundant PR creation logic previously found in other developer skills, promoting a more efficient and standardized workflow across the system.
Highlights:
- Skill Renaming and Consolidation: The 'pr-summary' skill has been renamed to 'pr-manager' and its scope significantly expanded to manage the entire Pull Request (PR) lifecycle.
- Centralized PR Workflow: The new 'pr-manager' skill now encompasses a comprehensive 5-step PR workflow: generating a summary, creating a draft PR, waiting for CI to pass, marking the PR as ready for review, and finally merging the PR.
- Standardized PR Body Format: A detailed and structured PR body format template has been integrated into the 'pr-manager' skill, promoting consistency across PR descriptions.
- Reduced Duplication: The 'autonomous-developer' and 'semi-autonomous-developer' skills have been refactored to remove duplicated PR creation logic, now referencing the centralized 'pr-manager' skill.
- Dependency Diagram Updates: The 'skill_dependencies.puml' diagram has been updated to include the new 'pr-manager' skill and reflect the updated dependencies for 'autonomous-developer' and 'semi-autonomous-developer'.
COMPLETED Fix valgrind errors in nightly code
- lots of errors in eventing tests, but just for clang.
- 1 new possible leak for both clang and gcc.
COMPLETED Create security module code
This pull request establishes a dedicated ores.security component to consolidate and manage all shared security primitives within the project. It systematically extracts and relocates cryptographic operations and validation utilities from existing modules like ores.iam and ores.connections. The refactoring also introduces modern C++ practices, such as RAII for OpenSSL resources, to enhance code reliability and maintainability. This change centralizes security logic, making it easier to manage, audit, and extend in the future.
Highlights:
- New Component Creation: A new component, ores.security, has been introduced to centralize shared security primitives, promoting better organization and reusability of security-related code.
- Code Migration and Refactoring: Existing security code, including password management and encryption services, has been migrated from ores.iam and ores.connections into the new ores.security component. This involved renaming classes (e.g., password_manager to password_hasher, encryption_service to encryption) and their methods for clarity and consistency within the new structure.
- RAII Pattern for OpenSSL Contexts: The RAII (Resource Acquisition Is Initialization) pattern has been applied to OpenSSL cipher context management using std::unique_ptr with a custom deleter (EVP_CIPHER_CTX_free). This significantly improves memory safety by ensuring automatic resource cleanup, eliminating manual cleanup on error paths, and making the code more robust.
- CMake and Build System Updates: The CMake build system has been updated to include the new ores.security component and adjust dependencies in ores.cli, ores.connections, and ores.iam to link against the new security library.
COMPLETED Prodigy should support multiple environments code
Now that we are running multiple claudes, qwens and geminis, it is often the case that we need to run a service from two environments. At present we cannot do this without a lot of effort. Ideally prodigy should just show all environments in one buffer and we can choose what to run.
COMPLETED Add named environment sets code
At present we are having to supply the port name and host which is fine when we have a single environment. However, because we have so many instances on the go at the same time, it is a bit painful to have to remember ports for each environment. Ideally we want a client side list of servers and the UI to go with it.
We need environment management, where we can add new connections and new folders. Folders can contain sub-folders. Environments can have names and tags. User can add tags. Data is stored in local SQL Lite database. Passwords are hashed.
Then in Qt we have an environment manager which has the UI for adding new environments, etc. We should have a "test connection" button.
Notes:
- need to be able to export to JSON the data and import from JSON. Must have option to exclude usernames and or passwords.
- need to add commands to shell for this.
- Core support
This pull request delivers a brand new ores.connections component, establishing a robust system for managing server connection bookmarks. It encompasses a well-defined domain model for organizing connections hierarchically and by tags, backed by secure SQLite persistence. The component features AES-256-GCM encryption for sensitive credentials and exposes a user-friendly service layer for all management operations, all thoroughly validated with extensive unit tests.
Highlights:
- New Component: ores.connections: Introduces a dedicated component for managing server connection bookmarks, providing a structured way to store and organize connection details.
- Domain Modeling: Defines core domain types including 'folder' for hierarchical organization, 'tag' for flexible categorization, 'server_environment' for connection details, and 'environment_tag' for many-to-many relationships, complete with JSON and table I/O support.
- Secure Persistence: Implements SQLite-based local persistence with a manually defined schema, including foreign keys and cascade delete rules, ensuring data integrity. Passwords are securely stored using AES-256-GCM encryption with PBKDF2 key derivation.
- High-Level API: Provides a 'connection_manager' service as a high-level API to interact with the connection data, abstracting away the underlying storage and encryption complexities.
- Comprehensive Testing: Includes a robust test suite with 79 test cases covering the domain objects, repository layer, and service layer, ensuring the reliability and correctness of the new component.
- Qt UI Support
This pull request significantly enhances the application's connection management capabilities by introducing a dedicated Connection Browser. This new feature allows users to securely store, organize, and manage their server connections using a hierarchical structure and master password encryption. It streamlines the login process by enabling pre-filled connection details and automatic submission, while also providing robust tools for managing connection data and ensuring a smoother user experience.
Highlights:
- Connection Browser MDI Window: Introduced a new MDI window for managing saved server connections, featuring a hierarchical tree view for folders and environments. This allows users to organize and access their connections efficiently before logging in.
- Secure Credential Management: Implemented master password support using AES-256-GCM encryption for securing saved server credentials. This includes features to create, change, and unlock access to encrypted passwords, enhancing security for stored connection details.
- CRUD Operations for Connections and Folders: Added comprehensive Create, Read, Update, and Delete (CRUD) functionalities for both connection folders and individual server environments within the Connection Browser, providing full control over saved configurations.
- Database Purge and Connection Handling: Included a 'Purge Database' action to reset all saved connections and folders. The system now also gracefully handles attempts to connect while already connected, prompting the user to disconnect first.
- Enhanced Login Experience: The Login Dialog now supports pre-filling connection details from saved entries and an auto-submit mode for seamless login when all credentials (including password) are available.
- Icon Guidelines Update: Updated the icon guidelines documentation to include new icons for 'Delete Dismiss', 'Key Multiple', and 'Server Link', reflecting the new functionalities.
COMPLETED Rename risk to refdata code
We need to split risk from ref data.
This pull request executes a significant refactoring effort by renaming a core component from ores.risk to ores.refdata. The change aims to clarify the component's role within the system, emphasizing its function in managing reference data rather than performing risk calculations. The scope of this change is broad, touching upon various layers of the application, from build configurations and source code to documentation and architectural diagrams, ensuring consistency and improved semantic clarity across the entire project.
Highlights:
- Component Rename: The ores.risk component has been comprehensively renamed to ores.refdata to better reflect its purpose as a reference data module for ORE (Open Source Risk Engine).
- Codebase-Wide Updates: This rename involved updating all include paths from ores.risk/ to ores.refdata/, changing the C++ namespace from ores::risk to ores::refdata, and modifying CMake targets (e.g., ores.risk.lib to ores.refdata.lib).
- Header Guard and File Renames: Header guards were updated from ORES_RISK_* to ORES_REFDATA_*, and risk_routes.cpp was renamed to refdata_routes.cpp in the HTTP server.
- Documentation and Diagram Synchronization: All PlantUML diagrams and various documentation files (e.g., sprint backlogs, skill definitions) were updated to correctly reference the new component name and aliases.
COMPLETED Prefix database entities with component code
The database is becoming a bit confusing and we can't tell what entities belong where. We need to prefix them by component, e.g. "accounts" becomes "iam_accounts".
This pull request introduces a fundamental refactoring of the SQL database schema by implementing a new, consistent naming convention across all entities. The primary goal is to enhance the organization and readability of the database, making it easier to understand the purpose and ownership of each object. This change facilitates better integration with the C++ codebase and streamlines future schema evolution by providing clear guidelines for naming new components.
Highlights:
- Consistent Naming Convention: All SQL tables, functions, triggers, and rules now adhere to a strict {component}_{entity}_{suffix} naming pattern, improving clarity and maintainability.
- Component Prefixes: New component prefixes (e.g., iam_, refdata_, assets_, telemetry_, geo_, variability_, utility_) have been introduced to align SQL entities with their corresponding C++ components.
- Standardized Suffixes: Entity suffixes like _tbl for tables, _fn for functions, _trg for triggers, _rule for rules, and various index suffixes (_idx, _uniq_idx, _gist_idx) are now consistently applied.
- C++ Code Alignment: Corresponding C++ entity files have been updated to reflect the new SQL table names in their tablename constants, ensuring synchronization between code and schema.
- Enhanced Documentation: The sql-schema-creator documentation has been significantly expanded to detail the new naming conventions, provide examples, and list existing entities by component, serving as a comprehensive guide for future development.
COMPLETED Implement data quality code
Originally we added seed data more or less haphazardly to the system. We now need to clean this up. We need to have a user driven way to inject sample data in the system, and the sample data must be curated carefully in order to preserve it's lineage and provenience.
- all data must have a source, a date at which it was sourced and a licence (if available). We should record who sourced it (email, name).
- data should be marked as synthetic (generated), primary or derived. Unless there is a data quality classification.
- data should be organised into collections / data sets.
- all data should be stored in the database, we probably don't even need c++ representation for it. There should be a stored procedure that copies data from sample tables to actual tables.
Notes:
- rename drop all script to drop schema.
- enum tables are using UUIDs. use the enum name instead.
- Analysis from Qwen
- Core Concepts
Concept Description Dataset A logical collection of sample records (e.g., a set of trades, portfolios, or market data snapshots). Record An individual row or entity within a dataset (optional granularity; lineage may be tracked at dataset or record level). Provenance The origin of the data—external vendor, internal system, or synthetic generator. Classification Categorizes the nature of the data for compliance and usage control. Lineage Directed acyclic graph (DAG) linking derived data to its upstream sources. Temporal Context Captures both business time (as_of_date) and system time (ingestion_timestamp), supporting bi-temporal reasoning. Data Passport A self-contained metadata manifest (relational or document-based) that answers the 5 Ws of data governance.
- Core Concepts
- Metadata Attributes
Each dataset (or optionally each record) must carry the following metadata fields.
- Provenance & Classification
Field Type Required Description source_system_id String (UUID or mnemonic) ✅ Identifier of the originating system (e.g., "BLOOMBERG", "INTERNAL_RISK_ENGINE_v2"). data_classification Enum ✅ One of: REAL, SYNTHETIC, OBFUSCATED, HYBRID. generation_method String / Enum ✅ if synthetic/hybrid Describes how data was created (e.g., "MONTE_CARLO", "REPLAY_OF_20231004", "BOOTSTRAP_FROM_PROD_SNAPSHOT"). business_context String ✅ Human-readable purpose (e.g., "Testing FX Forward P&L attribution", "Demo for client onboarding"). - B. Lineage & Derivation
Field Type Required Description upstream_derivation_id String (UUID) ❌ (required if derived) Points to the parent dataset or record ID from which this was derived. transformation_logic_ref URI / String ❌ (required if derived) Reference to the logic that produced this data (e.g., Git commit hash, script name, workflow ID). lineage_depth Integer ✅ Number of derivation steps from the original raw source (0 = raw/golden copy). - C. Temporal Metadata
Field Type Required Description as_of_date Date ✅ The business/market date the data represents (e.g., valuation date). ingestion_timestamp Timestamp (UTC) ✅ When the data entered the sample repository. valid_from Timestamp (UTC) ✅ Start of validity interval (for time-sliced data). valid_to Timestamp (UTC) ✅ End of validity interval (use far-future sentinel like 9999-12-31 for current). Note: valid_from/valid_to enable bi-temporal modeling—essential for replaying historical states in trading systems.
Granularity Options
Choose one of the following approaches based on your use case.
Option Description When to Use Dataset-level metadata One metadata record per dataset (e.g., per CSV file or table). For bulk samples where all rows share the same origin and transformation. Record-level metadata Each row carries its own metadata (via FK or embedded). When lineage varies per trade/portfolio (e.g., hybrid datasets mixing real and synthetic instruments). Data Passport Structure (Logical View)
Every sample dataset should be accompanied by a Data Passport manifest containing:
{ "who": "", "what": { "classification": "<SYNTHETIC|REAL|...>", "generation_method": "<...>" }, "where": { "upstream_derivation_id": "<UUID?>", "transformation_logic_ref": "<URI?>" }, "when": { "as_of_date": "YYYY-MM-DD", "ingestion_timestamp": "ISO8601 UTC", "valid_from": "ISO8601 UTC", "valid_to": "ISO8601 UTC" }, "why": "" }This can be stored as:
- A JSON/JSONB column in a relational table
- A standalone .passport.json file alongside Parquet/CSV
- A row in a metadata_registry table
Constraints & Validation Rules
- If data_classification ∈ {SYNTHETIC, HYBRID}, then generation_method must be non-null.
- If lineage_depth > 0, then upstream_derivation_id and transformation_logic_ref must be provided.
- valid_from ≤ valid_to
- as_of_date should align with valid_from/valid_to for consistency (e.g., as_of_date ∈ [valid_from, valid_to]).
- Provenance & Classification
COMPLETED Improvements to connection browser code
- can't drag and change order of folders.
- can't rename inline.
- We should validate the password to make sure it complies with password policies.
- add test connection to check the connection and credentials are correct.
- disable buttons are very bright, look enabled.
- connection browser should start with expanded tree.
- no tags support.
- login dialog should support connections from connection browser.
COMPLETED Modernise login dialog code
This pull request significantly overhauls the user authentication experience by introducing new, dark-themed login and signup dialogs. These dialogs are now modeless MDI subwindows, improving workflow and integration within the application. Key enhancements include automatic login after successful registration, a dropdown for quick access to saved connections, and a refreshed visual design.
Highlights:
- Modernized Login and Sign Up Dialogs: Introduced new dark-themed, modeless LoginDialog and SignUpDialog widgets, replacing older modal designs for a more integrated user experience.
- Streamlined User Registration: Implemented an auto-login feature that automatically authenticates a user after successful registration, reducing friction in the onboarding process.
- Enhanced Connection Management: Added a saved connections dropdown within the login dialog, allowing users to quickly select and connect to previously configured servers.
- MDI Subwindow Integration: The new login and sign-up dialogs are now presented as MDI subwindows, providing better window management and a more flexible UI layout.
COMPLETED History should have a revert button code
Rationale: Implemented.
It should be possible to choose a given version and ask the system to revert the currency to that version. It just makes an update with a new version to look like that version. It should also be possible to open at version. It shows the edit dialog in "read only mode" with the entity at that version. The tool bar should indicate this. It should also have a revert in that dialog.
COMPLETED Disconnect shows reconnect message code
Rationale: implemented.
When you click disconnect the status bar says "Reconnecting to server".
We can see but not edit. Also, test permissions to make sure they are being enforced.
COMPLETED Add UI support for data sets code
We did all of the database work but we cannot visualise the datasets.
Notes
- we need to check this issue across all triggers: inconsistent versioning. Done.
- UI Work
Gemini:
Data Librarian" is an excellent name. In financial institutions, the role of a Data Librarian (or Data Steward) is exactly what you are describing: someone who curates, catalogs, and ensures the provenance of "information books" (datasets) within the "library" (the trading system).
To manage the types you've created, the UI needs to handle Hierarchical Relationships (Domain > Subject Area) and Metadata Tagging (Dimensions & Coding Schemes).
- UI Conceptual Layout: The interface should be split into three functional
zones:
- The Stacks (Navigation): A sidebar for the hierarchy (Domain > Subject Area > Catalog).
- The Registry (Workspace): The main area to define Dimensions (Origin, Nature, Treatment) and Methodologies.
- The Archive (Dataset View): The specific view for individual Datasets and their Lineage.
- Dashboard Component: "The Collection Manager"This is where you would manage your Dimensions and Coding Schemes.
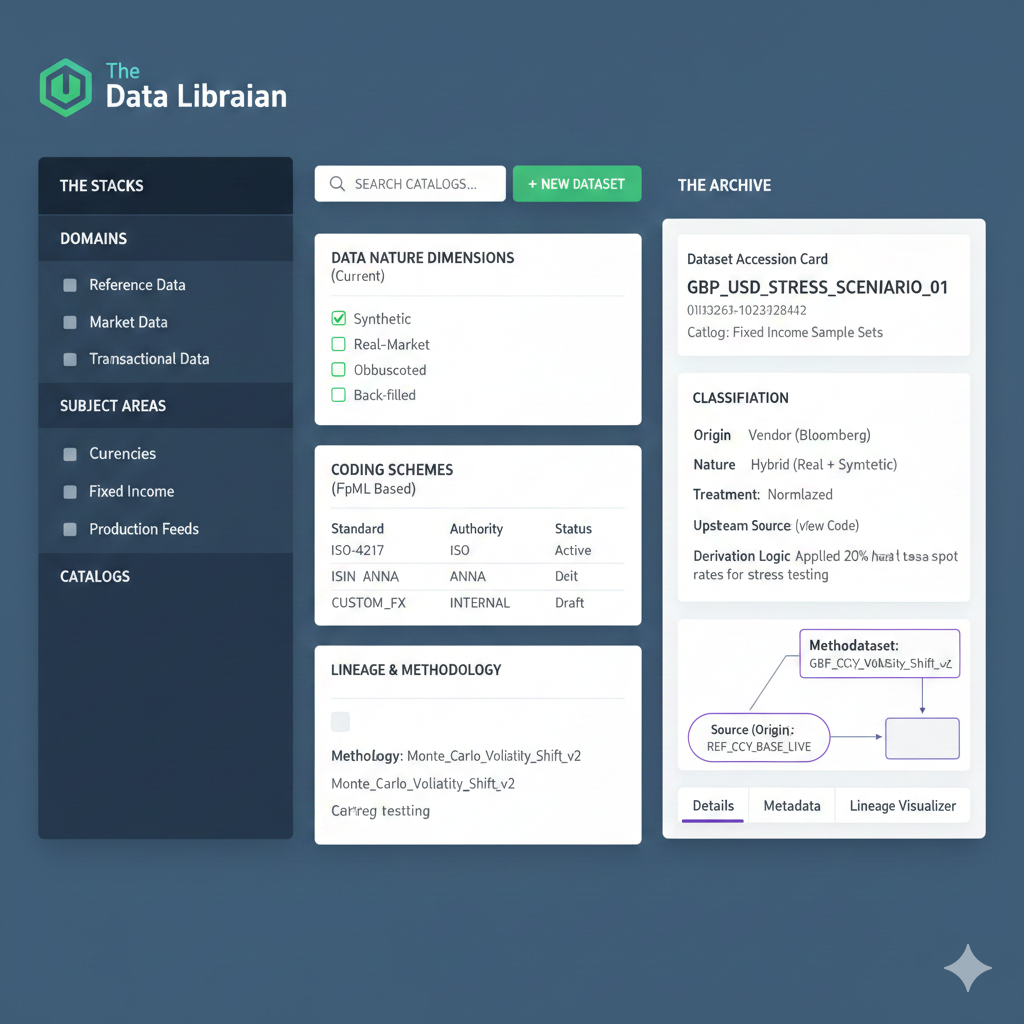
- Detailed View: "Dataset Accession Card" When you create or edit a Dataset
(UUID), the UI should present a "card" that forces the user to satisfy the
Lineage requirements you defined.
- Name: GBP_USD_STRESS_SCENARIO_01
- UUID: 550e8400-e29b-41d4-a716-446655440000 Catalog: Fixed Income Sample Sets***
- Classification Section (The Dimensions)
- Origin: Vendor (Bloomberg)
- Nature: Hybrid (Real + Synthetic)
- Treatment: Normalized
- Lineage & Methodology (The "Trace")
- Methodology: Monte_Carlo_Volatility_Shift_v2 [View Code]
- Upstream Source: REF_CCY_BASE_LIVE
- Derivation Logic: "Applied 20% haircut to base spot rates for stress testing."
- UI Nomenclature Suggestions: Since you are calling the tool Data Librarian,
lean into the metaphor to make the UI intuitive:
- Librarian: Catalog. The CollectionA curated group of related works.
- Dataset: The Volume. An individual instance of data.
- Methodology: The Formula. How the data was "written" or derived.
- Origin/Nature: Attributes. The "edition" details of the data.
- Coding Scheme: The Index. How the data is filed (ISIN, RIC, etc.).
Metadata Sidecar Logic: In your UI, you should have a "Lineage Visualizer" tab for every Dataset. This is crucial for your requirement of "adequately traced to a source." It should show a flow diagram:
Source (Origin) -> Methodology (Treatment) -> Target (Dataset)
Grok:
┌──────────────────────────────────────────────────────────────────────────────────────────────┐ │ Data Librarian v0.9.2 [Dark Theme] User: M.Craveiro │ ├───────────────┬──────────────────────────────────────────────────────────────────────────────┤ │ Stacks │ Collection Manager (The Registry) │ │ (Navigation) │ │ │ │ ┌──────────────────────────────────────────────────────────────┐ │ │ ▼ Domains │ │ Dimensions & Coding Schemes Catalog ▼ │ │ │ │ │ │ │ │ ┌──────────┐ │ │ [ + New Dimension ] [ + New Coding Scheme ] │ │ │ │ Fixed │ │ ├──────────────────────────────────────────────────────────────┤ │ │ │ Income │ │ │ Name │ Type │ Scope │ Status │ │ │ │ │ │ │────────────────────┼───────────┼────────────────┼────────────│ │ │ │ ▼ │ │ │ Origin │ Enum │ Global │ Locked │ │ │ │ Subject │ │ │ • Vendor │ │ │ │ │ │ │ Areas │ │ │ • Internal │ │ │ │ │ │ │ │ │ │ • Market │ │ │ │ │ │ │ ┌─────┐ │ │ │ Nature │ Enum │ Global │ Active │ │ │ │ │Rates│ │ │ │ • Raw │ │ │ │ │ │ │ │ │ │ │ │ • Normalized │ │ │ │ │ │ │ │ │ │ │ │ • Hybrid │ │ │ │ │ │ │ │Stres│ │ │ │ Treatment │ Enum │ Global │ Active │ │ │ │ │Scen.│ │ │ │ • As-is │ │ │ │ │ │ │ └─────┘ │ │ │ • Cleaned │ │ │ │ │ │ │ │ │ │ • Normalized │ │ │ │ │ │ │ Catalog │ │ │ RIC │ Coding │ Security │ Active │ │ │ │ ▼ │ │ │ ISIN │ Coding │ Security │ Active │ │ │ │ Fixed │ │ │ Bloomberg Ticker │ Coding │ Security │ Deprecated │ │ │ │ Income │ │ └──────────────────────────────────────────────────────────────┘ │ │ │ Sample │ │ │ │ └──────────┘ │ │ │ │ ┌───────────────────────────────┐ ┌───────────────────────────────┐ │ │ │ │ Recently Accessed Volumes │ │ Recently Modified Formulas │ │ │ │ │ • GBP_USD_STRESS_SCENARIO_01 │ │ • Monte_Carlo_Volatility_Shift│ │ │ │ │ • EUR_IR_CURVE_2025_Q4 │ │ _v2 │ │ │ │ │ • US_TREASURY_PAR_CURVE_D │ │ • FX_FWD_POINT_BOOTSTRAP_v3 │ │ │ │ └───────────────────────────────┘ └───────────────────────────────┘ │ ├───────────────┴──────────────────────────────────────────────────────────────────────────────┤ │ Dataset Accession Card – GBP_USD_STRESS_SCENARIO_01 [Close] │ ├──────────────────────────────────────────────────────────────────────────────────────────────┤ │ UUID: 550e8400-e29b-41d4-a716-446655440000 [Copy] │ │ Catalog: Fixed Income Sample │ │ Volume Name: GBP_USD_STRESS_SCENARIO_01 │ │ │ │ ┌─────────────────────────────┐ ┌─────────────────────────────┐ ┌──────────────────────┐ │ │ │ Classification (Dimensions) │ │ The Trace │ │ Metadata │ │ │ │ │ │ (Lineage & Methodology) │ │ Sidecar │ │ │ │ Origin : Vendor │ │ Methodology │ │ Version : 1.2 │ │ │ │ : Bloomberg │ │ Monte_Carlo_Volatility_ │ │ Status : Prod │ │ │ │ Nature : Hybrid │ │ Shift_v2 [View Code]│ │ Owner : Rates │ │ │ │ : Real + Synthetic│ │ │ │ Last Modified: 2026- │ │ │ │ Treatment : Normalized │ │ Upstream Sources │ │ 01-14 11:42 │ │ │ │ │ │ • REF_CCY_BASE_LIVE │ └──────────────────────┘ │ │ └─────────────────────────────┘ │ • USD_IR_CURVE_SOY_2025 │ │ │ │ │ │ │ │ Derivation Summary │ │ │ │ "Applied 20% haircut to │ │ │ │ base spot rates for stress │ │ │ │ testing purposes" │ │ │ └─────────────────────────────┘ │ ├──────────────────────────────────────────────────────────────────────────────────────────────┤ │ Lineage Visualizer (Flow) [Export SVG / PNG] │ │ │ │ ┌────────────────────┐ ┌────────────────────────────┐ ┌───────────────┐ │ │ │ Bloomberg │ │ Monte_Carlo_Volatility_ │ │ GBP_USD_STRESS│ │ │ │ REF_CCY_BASE_LIVE │ ────────►│ Shift_v2 │ ───────►│ _SCENARIO_01 │ │ │ │ (Live spot rates) │ 1:1 │ 20% volatility haircut │ 1:1 │ (Stress vol │ │ │ └────────────────────┘ └────────────────────────────┘ │ surface) │ │ │ └───────────────┘ │ │ │ │ [ + Add upstream ] [ Show full provenance tree ] [ Show data quality gates ] │ └──────────────────────────────────────────────────────────────────────────────────────────────┘
HF:
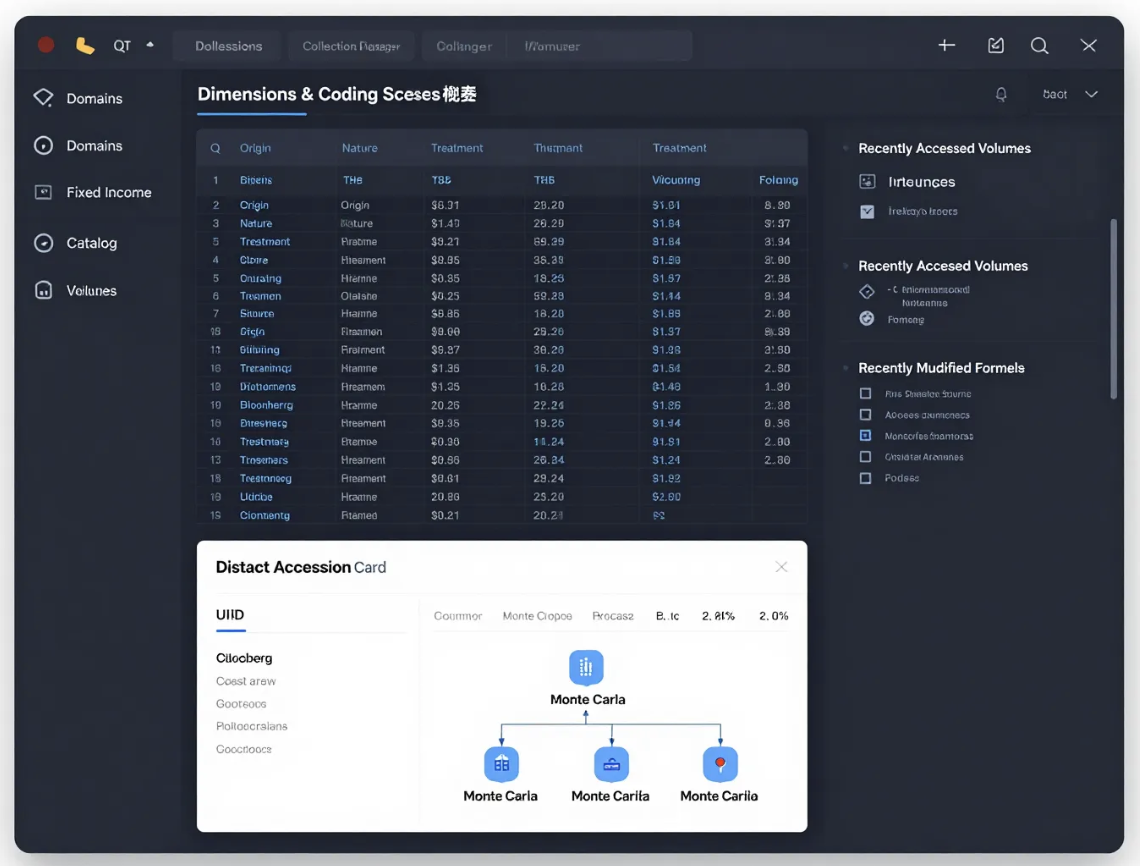
Implementation details:
This pull request significantly enhances the application's data management capabilities by introducing a comprehensive Data Librarian user interface. This new UI provides a centralized hub for users to explore, understand, and manage various datasets, complete with detailed metadata, data lineage visualization, and methodology documentation. Alongside this, new data sources like IP Geolocation mappings and visual assets have been integrated, expanding the breadth of available reference data. Performance and usability are also improved through network optimization and logical menu reorganization.
Highlights:
- Data Librarian UI: Introduced a new composite window for browsing and managing Data Quality (DQ) datasets, featuring a three-panel layout for dataset browsing, accession card details, and methodology information.
- IP Geolocation Data Infrastructure: Added a new DQ catalog for IP Geolocation data, including staging infrastructure for iptoasn.com data, and functions to populate the production database with IPv4 to country mappings.
- Visual Assets Catalog: Created a 'Visual Assets' catalog to centralize image data such as country flags and cryptocurrency icons, improving organization and reusability.
- Methodology Panel: Integrated a dedicated panel within the Data Librarian to display processing steps and implementation details for selected dataset methodologies, enhancing data transparency.
- UI Performance Improvement: Enabled the TCP_NODELAY option on network communications to mitigate Nagle's algorithm, resulting in faster loading times for parallel requests in the UI.
- Menu Restructuring: Refactored the main application menu, moving 'Identity' and 'Configuration' options under a unified 'System' menu, and consolidating data-related actions under a new 'Data' menu.
- Dataset Model Enhancements: Modified the ClientDatasetModel to include a 'Tags' column and custom roles for displaying Origin, Nature, and Treatment dimensions as visual badges in the dataset table. Origin Dimension Renaming: Renamed the 'Source' origin dimension to 'Primary' across the database schema and UI to better reflect its meaning as raw, untransformed data.
- UI Conceptual Layout: The interface should be split into three functional
zones:
- Subject areas
This pull request significantly enhances the application's data organization capabilities by introducing a new module for managing Subject Areas. It provides a structured way to define and track subject areas, complete with dedicated user interfaces for detailed viewing, editing, and a robust version history system. This integration improves the overall data governance and traceability within the application.
Highlights:
- New Subject Area Management Feature: Introduced a comprehensive system for managing 'Subject Areas', allowing users to create, view, edit, delete, and track the history of subject areas within data domains.
- Dedicated Controller and UI Components: Added a new SubjectAreaController to manage the lifecycle of subject area-related windows, along with SubjectAreaDetailDialog for individual subject area operations and SubjectAreaHistoryDialog for viewing version history and changes.
- Main Window Integration: The main application window (MainWindow) has been updated to include and initialize the SubjectAreaController, connect its signals to the status bar, and enable a new 'Subject Areas' action in the menu, making the feature accessible upon successful login.
- Version History and Revert Functionality: The SubjectAreaHistoryDialog provides a detailed view of a subject area's changes over time, including who made the change, when, and a commentary. It also enables opening read-only versions and reverting to previous states.
- Address review comments
This pull request significantly enhances the system's test suite and architectural design. It improves the quality and determinism of Data Quality (DQ) domain type tests through more thorough assertions and fixed time point generation. Crucially, it addresses and resolves a circular dependency between the DQ and Identity and Access Management (IAM) components by centralizing shared constants, leading to a more robust and maintainable codebase. The changes also include updates to internal documentation and system diagrams to reflect these structural improvements.
Highlights:
- Improved Test Assertions for DQ Domain Types: Enhanced test assertions for Data Quality (DQ) domain types, including explicit checks for audit fields like 'recorded_by' and 'change_commentary', as well as verification of table headers and field values in table conversion tests.
- Deterministic Time Values in Tests: Introduced a 'make_timepoint' helper function to generate fixed, deterministic time values for 'std::chrono::system_clock::time_point' fields in tests, ensuring repeatability and reliability.
- Updated Skill Documentation: Added new guidance to skill documentation for binary protocol developers and domain type creators, covering best practices for passing authorization services to message handlers and comprehensive domain type testing.
- Circular Dependency Resolution: Resolved a circular dependency between the 'ores.dq' and 'ores.iam' components by relocating the 'change_reason_constants.hpp' header to the more foundational 'ores.database' module, improving architectural modularity.
- System Model and CMake Dependency Updates: Synchronized the system model diagrams ('ores.puml') and CMake configurations across various projects ('ores.cli', 'ores.comms.shell', 'ores.dq', 'ores.iam') to accurately reflect the updated component dependencies, particularly concerning the DQ subsystem and the centralized change reason constants.
- Messaging
This pull request significantly expands the ORE Studio binary protocol by integrating a new Data Quality (DQ) subsystem. This enhancement provides robust messaging capabilities for managing a wide array of data quality entities, centralizing related functionalities. The changes also involve a re-architecture of existing change management features, moving them into the new DQ domain, which necessitates a protocol version update to ensure compatibility and reflect the breaking nature of this re-organization.
Highlights:
- New Data Quality (DQ) Subsystem: A dedicated subsystem (0x6000-0x6FFF) has been introduced to the ORE Studio binary protocol to manage Data Quality related messages and entities.
- Comprehensive DQ Messaging Protocols: New messaging protocols are added to support CRUD (Create, Read, Update, Delete) and history operations for various data quality entities, including catalogs, data domains, subject areas, datasets, methodologies, coding schemes, and dimensions (nature, origin, treatment).
- Migration of Change Management Messages: Existing change management messages (for change reasons and categories) have been relocated from the IAM subsystem (0x2050-0x2061) to the new DQ subsystem (0x6070-0x6081). This is a breaking change in message type IDs.
- Binary Protocol Version Update: The ORE Studio binary protocol version has been incremented from 21.3 to 22.0 to reflect the introduction of the new DQ subsystem and the breaking changes associated with message re-organization.
- Dedicated DQ Message Handling: A new dq_message_handler and its registrar have been implemented to process all incoming messages within the new Data Quality subsystem, ensuring proper routing and business logic execution for DQ-related requests.
- Data catalog work
This pull request significantly enhances the data quality management framework by introducing a new dq_catalog entity, which serves as a high-level grouping mechanism for related datasets. Concurrently, it undertakes a major refactoring of the Entity-Relationship (ER) diagram, standardizing table naming conventions, reorganizing entities into component-based packages, and incorporating a comprehensive set of data quality entities, as well as new telemetry and geolocation domains. These changes aim to improve data organization, clarity, and the overall structural integrity of the database schema.
Highlights:
- New Data Quality Catalog Entity: Introduced dq_catalog_tbl as a top-level grouping mechanism for datasets within the data quality domain, allowing for logical organization of related data.
- ER Diagram Standardization and Expansion: The Entity-Relationship (ER) diagram (ores_schema.puml) has undergone a major overhaul, implementing a consistent <component>_<entity>_tbl naming convention across all tables and reorganizing packages by component prefix (e.g., iam, assets, refdata, variability, dq, telemetry, geo).
- Comprehensive Data Quality Entities: All missing Data Quality (DQ) entities, including dimensions (nature, origin, treatment), methodology, dataset, and various artefact tables, have been added to the ER diagram, enhancing the data quality framework.
- Integration of Telemetry and Geolocation Domains: New telemetry and geolocation domains, along with their respective tables (telemetry_logs_tbl and geo_ip2country_tbl), have been integrated into the ER diagram.
- Dataset Assignment to Catalogs: Initial population scripts for dq_catalog_tbl have been added, creating 'ISO Standards' and 'Cryptocurrency' catalogs, and existing datasets are now assigned to these new catalogs.
- Domain types
This pull request significantly expands the data quality (DQ) infrastructure by introducing a comprehensive set of domain types designed to manage and track data integrity. It establishes foundational structures for organizing data, defining classification schemes, and documenting processing methodologies. The integration of FpML reference data further enriches the system's ability to handle complex financial data, while new data generators streamline testing workflows. These changes collectively enhance the robustness and traceability of data within the system.
Highlights:
- New Data Quality Domain Types: Introduced 10 new domain types for Data Quality (DQ) database entities, including data_domain, subject_area, catalog, coding_scheme_authority_type, coding_scheme, origin_dimension, nature_dimension, treatment_dimension, methodology, and dataset. These types support JSON I/O and table I/O.
- FpML Reference Data Integration: Incorporated FpML non-ISO currencies, business centers, and business processes reference data. This includes new XML data files and corresponding SQL population scripts to integrate these financial standards into the DQ system.
- Synthetic Data Generators: Added test data generators for all new DQ domain types using faker-cxx, facilitating the creation of synthetic data for testing and development purposes.
- Date Serialization Support: Implemented a year_month_day reflector to enable proper serialization of std::chrono::year_month_day objects with reflect-cpp, ensuring consistent date handling.
- Enhanced Data Quality Documentation: Expanded documentation for data quality concepts, including the 'DQ 6' standard dimensions (Accuracy, Completeness, Consistency, Timeliness, Validity, Uniqueness) and relevant industry bodies like DAMA-DMBOK and TOGAF.
COMPLETED Add schemes for countries and currencies code
Rationale: implemented.
We should have data lineage where possible. There should be a table telling us where we sourced countries, currencies etc. Even permissions/roles, if there are Qany specs on this. There should be an entry for "internal".
COMPLETED Add a data library or collection code
Rationale: implemented.
Datasets are logically related. We should have collections of datasets designed to work together.
COMPLETED Refactor Qt icon implementation code
At present we have a lot of hard-coding on icons. We need to make this code a bit more maintainable and also to support changing icon theme in the future.
- Refactor Icon use
This pull request significantly refactors how icons are managed and used throughout the Qt application. By introducing semantic enumerations for icons and themes, and centralizing the logic for retrieving and recoloring them, the changes aim to improve code maintainability, consistency, and flexibility for future UI adjustments. This update touches a large portion of the UI-related C++ files, standardizing icon instantiation.
Highlights:
- Centralized Icon Management: Introduced enum class Icon and enum class IconTheme in IconUtils.hpp to provide a semantic and theme-aware way to reference application icons, replacing scattered string literals for SVG paths.
- Streamlined Icon Retrieval and Recoloring: Added new static methods iconPath and an overloaded createRecoloredIcon to IconUtils, allowing icons to be retrieved and recolored using the new enums, simplifying icon usage throughout the codebase.
- Standardized Icon Colors: Defined common icon colors (e.g., DefaultIconColor, ConnectedColor, DisconnectedColor) as static inline constants within IconUtils.hpp, promoting consistency and easier modification of UI themes.
- Extensive Codebase Update: Updated numerous files across various controllers, dialogs, and MDI windows to adopt the new icon management system, replacing direct SVG path strings and hardcoded colors with the Icon enum and IconUtils methods.
- New Icon Resources: Added a comprehensive set of Solarized (Linear and Bold) SVG icons to resources.qrc, expanding the available icon themes.
- Dependency Update: The vcpkg submodule has been updated to a newer commit, indicating potential library updates or build system changes.
COMPLETED Data Librarian improvements code
Notes:
- rename methods to methodology.
- graph is not reflecting collection dependencies nor lineage dependencies.
- should be able to insert collections into system from dialog. Remove insert from scripts.
- use word wrap in methodology and data Ascension
- rename data Ascension to data passport.
- instead of showing dataset properties in main data librarian window, create a information. Tabs should be on the left hand side.
- add licence to FPML data: https://www.fpml.org/the_standard/fpml-public-license/
This pull request significantly enhances the data quality (DQ) subsystem by introducing a robust dataset publication mechanism. It enables users to promote curated datasets to production environments with confidence, managing complex inter-dataset dependencies and providing clear audit trails. The changes span backend services, database schema, and the user interface, delivering a complete and intuitive experience for data librarians.
Highlights:
- Dataset Publication Workflow: Implemented a comprehensive workflow for publishing datasets from staging (artefact) tables to production tables, including dependency resolution, configurable publication modes (upsert, insert_only, replace_all), and audit logging.
- Dependency Resolution: Introduced stable dataset codes for referencing dependencies and integrated Boost.Graph for topological sorting to ensure datasets are published in the correct order, with dependencies preceding dependents.
- UI Enhancements: Developed a multi-page wizard for publishing datasets with progress indication, a dedicated dialog for tracking publication history, and updated the dataset detail view to visualize dependencies.
- Database Schema & API Updates: Renamed 'catalog_dependency' to 'dataset_dependency' across the stack, added a 'role' field to dependencies, and updated messaging protocols and database schemas to support the new dataset codes and publication features.
- Improved Upsert Logic: Fixed the upsert mode in population functions to properly update existing records with version increments, ensuring data integrity and correct behavior during publication.
POSTPONED Implement party related entities at database level code
The first step of this work is to get the entities to work at the database schema level.
- Table Structure: party
Field Name Data Type Constraints Commentary party_idInteger PK, Auto-Inc Internal surrogate key for database performance and foreign key stability. tenant_idInteger FK (tenant) The "Owner" of this record. Ensures GigaBank's client list isn't visible to AlphaHedge. party_nameString(255) Not Null The full legal name of the entity (e.g., "Barclays Bank PLC"). short_nameString(50) Unique A mnemonic or "Ticker" style name used for quick UI displays (e.g., "BARC-LDN"). leiString(20) Unique/Null The ISO 17442 Legal Entity Identifier. Critical for regulatory reporting and GLEIF integration. is_internalBoolean Default: False Flag: If TRUE, this party represents a branch or entity belonging to the Tenant (The Bank). party_type_idInteger FK (scheme) Categorizes the entity: Bank, Hedge Fund, Corporate, Central Bank, or Exchange. postal_addressText Used for generating legal confirmations and settlement instructions. business_center_idInteger FK (scheme) Links to an FpML Business Center (e.g., GBLO, USNY). Determines holiday calendars for settlement. statusEnum Active/Inactive Controls whether trades can be booked against this entity. created_atTimestamp Audit trail for when the entity was onboarded.
POSTPONED Refactor documentation infra
- split recipes per entity.
- create a top-level "domain" document per entity which cross-references recipes, component model, entity implementation files (including SQL), skills.
- recipes should belong to the component rather than being global.
- Site fixes
This pull request primarily focuses on improving the stability and reliability of the site build process by introducing robust error handling and preventing debugger interruptions. Concurrently, it addresses and resolves critical broken internal links within the project's documentation, enhancing the overall user experience and information accessibility. Minor updates to agile sprint tracking documentation are also included.
Highlights:
- Build Process Robustness: Implemented error handling for the org-publish-all function across all build scripts (.build-plan.el, .build-site.el, .build-skills.el) to gracefully catch and report build failures instead of crashing. Additionally, Emacs debugger and quit-on-error behaviors are suppressed during the build to ensure uninterrupted execution.
- Broken Link Fixes: Corrected several broken internal links within the doc/recipes/cli_recipes.org file by updating outdated UUIDs for the ORE Studio Geo and Telemetry Components, ensuring accurate navigation within the documentation.
- Documentation Updates: Updated clock table entries and summaries in doc/agile/v0/sprint_backlog_09.org to reflect recent work, and added new notes and observations related to the 'Clean up seed data' task.
COMPLETED Add fake world dataset code
We have spec'd out the "fake world" data set. Use it to test that dataset infrastructure is setup correctly.
Footer
| Previous: Version Zero |