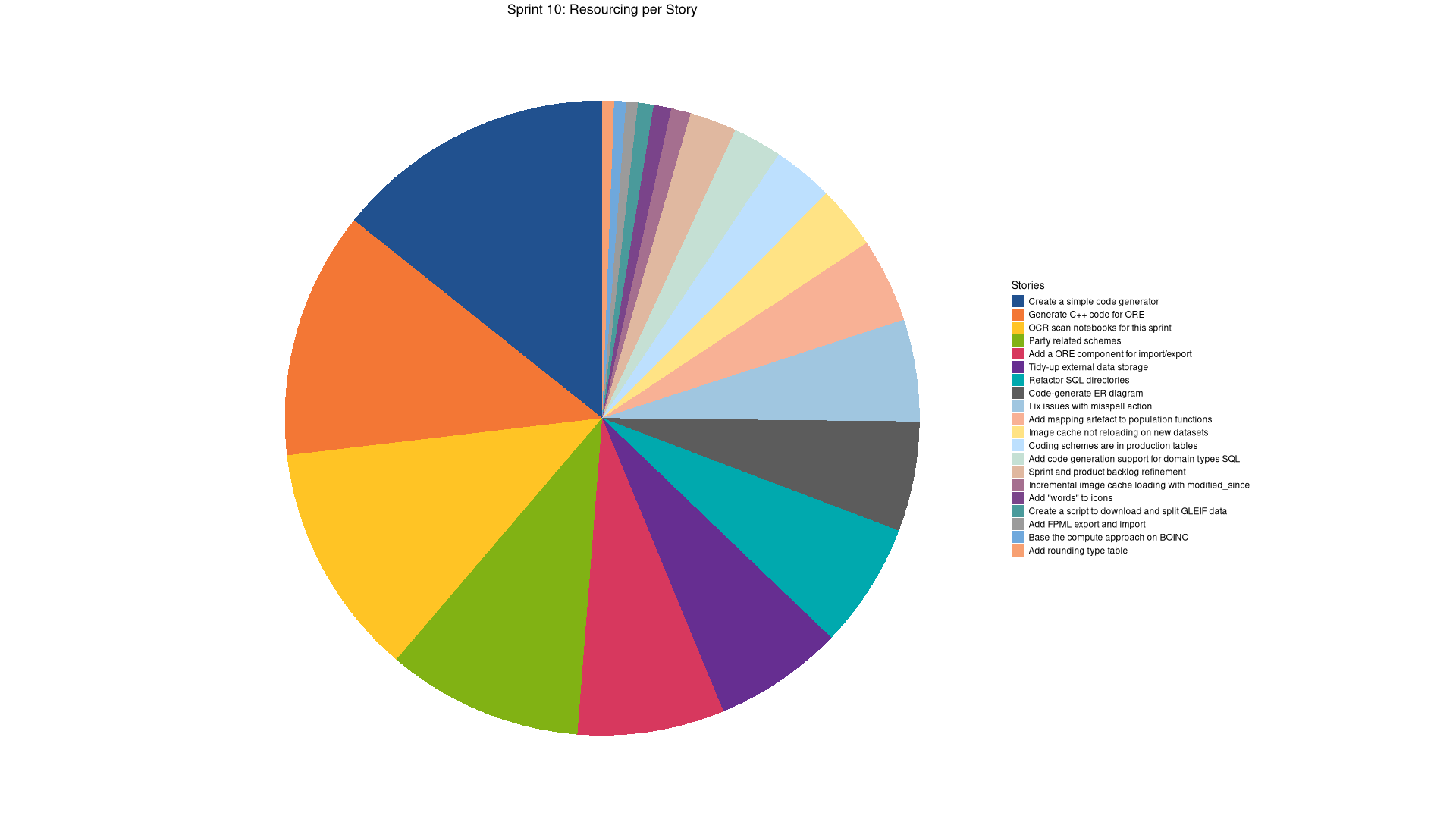
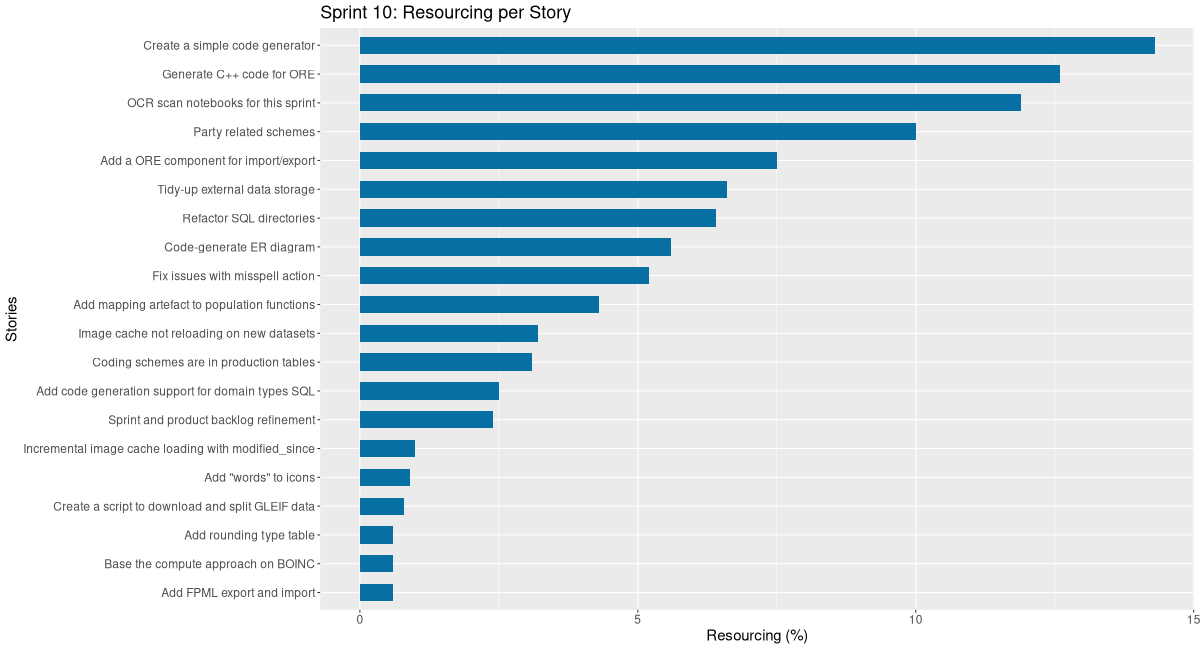
Sprint Backlog 10
Sprint Mission
- Data quality and code generation work.
Stories
Active
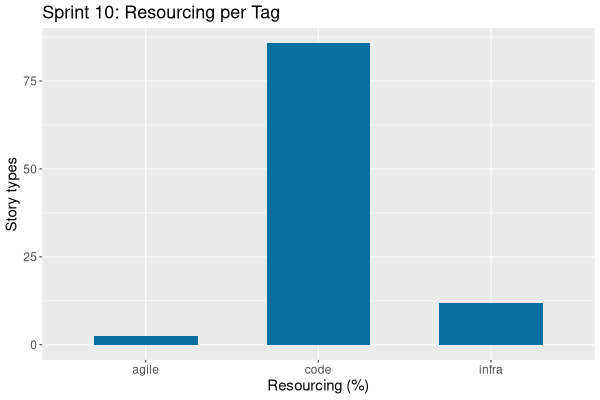
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 10:41 | 100.0 | |||
| Stories | 10:41 | 100.0 | |||
| Active | 10:41 | 100.0 | |||
| code | Separate catalog metadata schema from production data | 0:28 | 4.4 | ||
| code | Add dataset bundles | 4:53 | 45.7 | ||
| code | Fix issues with xsdcpp when generating ORE code | 0:11 | 1.7 | ||
| code | Add UI for bootstrapping from Qt | 3:48 | 35.6 | ||
| code | Fix code review comments for librarian | 1:21 | 12.6 |
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 74:01 | 100.0 | |||
| Stories | 74:01 | 100.0 | |||
| Active | 74:01 | 100.0 | |||
| agile | Sprint and product backlog refinement | 1:17 | 1.7 | ||
| infra | OCR scan notebooks for this sprint | 7:06 | 9.6 | ||
| code | Create a simple code generator | 7:38 | 10.3 | ||
| code | Party related schemes | 5:20 | 7.2 | ||
| code | Image cache not reloading on new datasets | 1:43 | 2.3 | ||
| code | Create a script to download and split GLEIF data | 0:25 | 0.6 | ||
| code | Incremental image cache loading with modified_since | 0:31 | 0.7 | ||
| code | Fix issues with misspell action | 2:47 | 3.8 | ||
| code | Tidy-up external data storage | 3:33 | 4.8 | ||
| code | Coding schemes are in production tables | 1:39 | 2.2 | ||
| code | Refactor SQL directories | 3:24 | 4.6 | ||
| code | Code-generate ER diagram | 3:01 | 4.1 | ||
| code | Add "words" to icons | 0:28 | 0.6 | ||
| code | Add mapping artefact to population functions | 2:19 | 3.1 | ||
| code | Add a ORE component for import/export | 4:00 | 5.4 | ||
| code | Fix windows CI break due to XSD code generation | 0:18 | 0.4 | ||
| code | Clean up data layers | 1:21 | 1.8 | ||
| code | Add rounding type table | 1:37 | 2.2 | ||
| code | Add code generation support for domain types SQL | 1:20 | 1.8 | ||
| code | Separate catalog metadata schema from production data | 0:43 | 1.0 | ||
| code | Generate C++ code for ORE | 6:43 | 9.1 | ||
| code | Add dataset bundles | 8:19 | 11.2 | ||
| code | Fix issues with xsdcpp when generating ORE code | 0:11 | 0.2 | ||
| code | Add UI for bootstrapping from Qt | 6:20 | 8.6 | ||
| code | Fix code review comments for librarian | 1:21 | 1.8 | ||
| code | Add FPML export and import | 0:19 | 0.4 | ||
| code | Base the compute approach on BOINC | 0:18 | 0.4 |
STARTED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
COMPLETED OCR scan notebooks for this sprint infra
We need to scan all of our finance notebooks so we can use them with AI. Each sprint will have a story similar to this until we scan and process them all.
COMPLETED Create a simple code generator code
We keep running out of claude code tokens. One way out of it is to generate the basic infrastructure via code generation and then use claude to fix any issues.
COMPLETED Add party identifier scheme entity code
The following is the analysis for adding support to party schemes.
List of schemes to seed in SQL:
- party identifier scheme: LEI
- Name: Legal Entity Identifier
- URI: http://www.fpml.org/coding-scheme/external/iso17442
- Description: Legal Entity Identifier (ISO 17442, 20-char alphanumeric). Global standard for legal entities.
- party scheme: BIC
- Name: Business Identifier Code
- URI: http://www.fpml.org/coding-scheme/external/iso9362
- Description: Business Identifier Code (SWIFT/BIC, ISO 9362). Used for banks and financial institutions.
- party scheme: MIC
- Name: Market Identifier Code
- URI: http://www.fpml.org/coding-scheme/external/iso10383
- Description: Market Identifier Code (ISO 10383). Identifies trading venues (e.g., XNYS, XLON). Note: Technically a venue, but often linked to party context in trade reports.
- party scheme: CEDB
- Name: CFTC Entity Directory
- URI: http://www.fpml.org/coding-scheme/external/cedb
- Description: CFTC Entity Directory (US-specific). Used in CFTC swap data reporting for non-LEI entities.
- party scheme: Natural Person
- Name: Natural Person
- URI: http://www.fpml.org/coding-scheme/external/person-id
- Description: Generic identifier for individuals (e.g., employee ID, trader ID). Not standardized; value interpreted contextually.
- party scheme: National ID
- Name: National Identifier
- URI: http://www.fpml.org/coding-scheme/extern/national-id
- Description: National identifiers (e.g., passport number, tax ID, SIREN, ORI, national ID card). Covers MiFID II “client identification” requirements.
- party scheme: Internal
- name: Internal
- URI: http://www.fpml.org/coding-scheme/external/party-id-internal
- Description: Proprietary/internal system identifiers (e.g., client ID in your OMS, CRM, or clearing system).
- party scheme: ACER Code
- name: EU Agency for Energy Regulation
- URI: http://www.fpml.org/coding-scheme/external/acer-code
- Description: ACER (EU Agency for Energy Regulation) code. Required for REMIT reporting by non-LEI energy market participants. Officially supported in FpML energy extensions.
- party scheme: DTCC Participant ID
- Name: Depository Trust & Clearing Corporation Participant ID
- URI:
- Description: DTCC Participant ID: A unique numeric identifier (typically 4–6 digits) assigned by the Depository Trust & Clearing Corporation (DTCC) to member firms authorized to participate in U.S. clearing and settlement systems, including DTC, NSCC, and FICC. Used in post-trade processing, trade reporting, and regulatory submissions in U.S. capital markets.
- party scheme: AII / MPID
- Name: Alternative Trading System (ATS) Identification Indicator / Market Participant ID
- Description: Commonly referred to as MPID – Market Participant Identifier; AII stands for ATS Identification Indicator, a term used in FINRA contexts. A four-character alphanumeric code assigned by FINRA (Financial Industry Regulatory Authority) to broker-dealers and alternative trading systems (ATSs) operating in U.S. equities markets. Used to identify the originating or executing firm in trade reports (e.g., in OATS, TRACE, or consolidated tape reporting). MPIDs are required for all SEC-registered trading venues and participants in U.S. equity and options markets.
COMPLETED Party related schemes code
We need to implement these before we can implement party:
- entity type
- party role
- local jurisdiction
- business center
- person role
- account types
- entity classifications
- local jurisdictions
- party relationships
- party roles
- person roles
- regulatory corporate sectors
- reporting regimes
- supervisory bodies
This pull request introduces a robust and automated system for managing FPML reference data within the platform. It significantly upgrades the codegen capabilities to parse FPML XML, generate comprehensive SQL database structures, and create scripts for populating both staging and production tables. The changes also streamline the data publication process by embedding key operational metadata directly into dataset definitions, moving towards a more configurable and less hard-coded approach for data management.
Highlights:
- FPML Reference Data Workflow: Implemented a complete Data Quality (DQ) artefact workflow for 15 FPML reference data entity types, encompassing 18 distinct datasets.
- SQL Schema Generation: Added automated SQL schema generation for FPML entities, including bi-temporal tables, notification triggers, and dedicated artefact staging tables.
- Image Linking: Introduced functionality to link business centres to country flags, enhancing visual representation within the data.
- Architecture Refinement: Refactored SQL generation to produce individual files per entity/coding-scheme instead of concatenated scripts, improving modularity and maintainability.
- Dataset Metadata Enhancement: Extended dataset records to directly store target_table and populate_function details, enabling more dynamic and flexible data publication.
COMPLETED Image cache not reloading on new datasets code
When we publish images, the image cache does not reload.
COMPLETED Create a script to download and split GLEIF data code
We need some data to drive the new Party tables. We can get GLEIF data for this. The dataset is too large, so we need to obtain a representative subset.
Links:
COMPLETED Incremental image cache loading with modified_since code
The ImageCache currently clears all cached images and re-fetches everything on reload. This is inefficient when only a few images have changed. We should track the last load time and only fetch images that have been modified since then.
The image domain already has a recorded_at timestamp field that tracks when
each image was last modified.
Required changes:
- Protocol (
assets_protocol.hpp):- Add
std::optional<std::chrono::system_clock::time_point> modified_sinceparameter tolist_images_request. - Add
recorded_atfield toimage_infostruct in the response.
- Add
- Server handler:
- Update the list_images handler to filter images where
recorded_at >modified_since= when the parameter is provided. - Return all images when
modified_sinceis not set (current behaviour).
- Update the list_images handler to filter images where
- Client ImageCache (
ImageCache.hpp/cpp):- Add
last_load_time_member to track when images were last loaded. - On
reload(), don't clear caches; instead sendmodified_sincewith last load time. - Only fetch and update images that were returned (changed since last load).
- Update
last_load_time_after successful load.
- Add
Acceptance criteria:
- When publishing an image dataset, only changed images are fetched.
- UI refresh is minimized (no flashing for unchanged images).
- Full reload still possible (e.g., on first load or explicit cache clear).
- Protocol is backward compatible (server handles missing
modified_since).
COMPLETED Fix issues with misspell action code
FPML and LEI data is breaking misspell action. Need to find a way to ignore folders.
This was complicated in the end because we relied on GLM 4.7, but it got very confused and kept suggesting approaches that were not very useful. In the end, fixed it manually.
COMPLETED Tidy-up external data storage code
At present we have external data all over the place, making it hard to understand what's what. We need to consolidate it all under https://github.com/OreStudio/OreStudio/blob/main/external.
This pull request introduces a significant refactoring of how reference data is managed and generated within the project. By reorganizing data into domain-specific directories, implementing manifest files for better source tracking, and developing code generators, the changes aim to streamline the process of maintaining and updating reference data. The relocation of external data and the introduction of master include files further enhance the system's structure and clarity, ultimately improving the robustness and maintainability of the data population process.
Highlights:
- Reference Data Reorganization: The populate directory has been restructured into domain-specific subdirectories, including fpml/, crypto/, flags/, and solvaris/, to improve organization and modularity.
- Manifest Files Introduction: New manifest.json files have been added for external data sources (flags, crypto) and internal solvaris data, providing a centralized way to manage data sources.
- Code Generator Creation: Dedicated code generators have been developed for flags, crypto, and solvaris metadata SQL, automating the generation of SQL files from source data.
- External Data Relocation: External data has been moved to a new 'external/' directory, accompanied by proper methodology documentation to clarify data sourcing and usage.
- Master Include Files: Master include files (e.g., fpml.sql, crypto.sql, flags.sql, solvaris.sql) have been added for each domain, simplifying the inclusion of related SQL scripts.
- Populate Ordering Fixes: The ordering of data population has been adjusted to resolve existing dataset dependency issues, ensuring correct data loading.
COMPLETED Coding schemes are in production tables code
We need to add datasets for coding schemes. At present they are going directly into production tables.
This pull request significantly refactors the management of ISO and FpML coding schemes by integrating them into a robust Data Quality (DQ) artefact pipeline. This change standardizes the process for handling external reference data, ensuring greater consistency and control over data publication. It introduces new database structures and functions to support a more governed lifecycle for these critical datasets, allowing for previewing changes and flexible update strategies, while maintaining direct insertion for specific internal party schemes.
Highlights:
- Standardized Coding Scheme Management: ISO and FpML coding schemes are now processed through a dedicated Data Quality (DQ) artefact pipeline, moving away from direct database insertions. This ensures a more consistent and governed approach to managing external reference data.
- Enhanced Data Governance: The new pipeline supports preview, upsert, insert-only, and replace-all modes for publishing coding schemes, offering greater control and consistency over data updates and lifecycle management.
- New Schema Components: A new staging table, dq_coding_schemes_artefact_tbl, has been introduced for temporary storage of coding schemes. Additionally, new functions dq_preview_coding_scheme_population() and dq_populate_coding_schemes() are provided to manage the publication process to production.
- Automated Generation and Dependencies: Code generators for ISO and FpML have been updated to produce artefact inserts for the new pipeline. Dependencies for ISO countries and currencies now correctly link to the new iso.coding_schemes dataset, ensuring proper ordering during data loading.
- Exclusion of Party Schemes: Certain party-related coding schemes (e.g., LEI, BIC, MIC) will continue to be handled via direct inserts, acknowledging their distinct, manually-defined nature and keeping them separate from the new pipeline.
COMPLETED Refactor SQL directories code
At present we have all files in one directory. As we add more tables it's becoming quite hard to follow.
Notes:
- user ores must be a variable.
- Restructure create, drop/teardown and update documentation
This pull request significantly refactors the SQL project's structure and database management processes. The primary goal is to enhance the organization of SQL creation scripts into logical components, improve the safety and auditability of database teardown operations, and update documentation to reflect these changes and provide clearer guidance. These changes streamline development workflows and reduce the risk of accidental data loss, particularly in production environments.
Highlights:
- Directory Structure Refactoring: The create/ directory has been reorganized from a flat structure into component-based subdirectories (e.g., iam/, dq/, refdata/, assets/), each with a master script to orchestrate its files.
- Enhanced Drop/Teardown Approach: The database teardown process has been restructured for improved traceability and safety. Production database drops now require explicit, reviewable SQL scripts generated by admin/admin_teardown_instances_generate.sql, moving away from pattern matching for critical databases. A centralized drop/drop_database.sql handles single database teardowns, and teardown_all.sql provides a comprehensive, confirmed cluster-wide cleanup.
- Documentation Cleanup and Updates: Outdated directory structure information has been removed from ores.sql.org and cross-references added to the SQL Schema Creator skill documentation. The ER diagram (ores_schema.puml) has been significantly updated to include 15 new refdata tables and 19 new data quality tables, reflecting a more complete schema.
- Stale Code Removal and Fixes: Thirteen stale entries have been removed from various drop scripts, and a redundant constraint drop in dq_tags_artefact_create.sql has been fixed, improving code cleanliness and efficiency.
- Refactor drop/ and populate/ directory structure
This pull request introduces a significant refactoring of the SQL script organization within the drop/ and populate/ directories. The changes aim to enhance modularity and maintainability by grouping related SQL files into component-specific subdirectories and establishing consistent naming conventions for master scripts. This restructuring simplifies navigation and management of database schema and data population scripts.
Highlights:
- Directory Structure Reorganization: The drop/ directory has been reorganized from a flat structure into component-based subdirectories, including assets, dq, geo, iam, refdata, seed, telemetry, utility, and variability.
- File Relocation and Git History Preservation: 56 SQL files have been moved into their respective new component subdirectories, with their git history preserved to maintain traceability.
- Consistent Naming Conventions: New component master files have been created with consistent naming patterns: drop_COMPONENT.sql and populate_COMPONENT.sql.
- Master Drop File Updates: The drop_all.sql file has been removed and replaced by drop/drop.sql, and drop_database.sql has also been relocated into the drop/ directory.
- Population Function Refactoring: The monolithic seed_upsert_functions_drop.sql has been split into individual per-component population function files (e.g., dq_population_functions_drop.sql, iam_population_functions_drop.sql), improving modularity.
- Populate Master File Alignment: All populate/ master files have been updated to align with the new consistent naming convention (populate_COMPONENT.sql).
- Refactor coding schemes and clean up ores.sql directory structure
This pull request significantly improves the maintainability and organization of the ores.sql project by standardizing directory structures and enforcing consistent naming conventions for administrative database objects. It also integrates FPML coding schemes into a more robust data quality pipeline, streamlining data management and generation processes. These changes enhance clarity, reduce technical debt, and ensure future scalability and ease of development.
Highlights:
- Coding Schemes Refactor: FPML coding schemes have been refactored to integrate with the DQ artefact pipeline, ensuring proper dataset management, fixing ordering and URI escaping, and consolidating codegen documentation.
- Directory Structure Reorganization: The projects/ores.sql directory has been cleaned up and reorganized. This includes removing deprecated/obsolete files, renaming the schema/ folder to create/, and introducing a utility/ folder for developer tools.
- Admin Database Object Naming Conventions: Admin database objects (files, functions, and views) now adhere to a consistent naming convention, using an admin_ prefix and _fn or _view suffixes where appropriate.
- C++ Code Updates: The C++ database_name_service has been updated to reflect the new admin_ prefixed SQL function names, ensuring compatibility with the refactored database utilities.
COMPLETED Code-generate ER diagram code
The diagrams are getting too out of line with the code, see if we can do a quick hack to code-generate them from source.
This pull request introduces a significant enhancement to the ores.codegen project by implementing an automated system for generating PlantUML Entity-Relationship diagrams directly from the SQL schema. This system not only creates visual representations of the database structure but also incorporates a comprehensive validation engine to enforce schema conventions, ensuring consistency and adherence to best practices. The new tooling streamlines documentation, reduces manual effort, and provides a single source of truth for the database design, making it easier for developers and stakeholders to understand and maintain the data model.
Highlights:
- Automated ER Diagram Generation: Introduced a new codegen system to automatically generate PlantUML Entity-Relationship (ER) diagrams directly from SQL CREATE/DROP statements.
- Comprehensive SQL Parsing: Developed a Python-based SQL parser (plantuml_er_parse_sql.py) capable of extracting detailed schema information including tables, columns, primary keys, unique indexes, and foreign key relationships.
- Intelligent Table Classification: The parser automatically classifies tables into categories like 'temporal', 'junction', and 'artefact' based on their column structure and naming conventions, applying appropriate stereotypes in the diagram.
- Convention Validation: Integrated a robust validation system that checks SQL schema against predefined naming, temporal table, column, drop script completeness, and file organization conventions, issuing warnings or failing builds in strict mode.
- Dynamic Relationship Inference: Relationships between tables are inferred based on foreign key column naming conventions and explicit references, supporting one-to-many and one-to-one cardinalities.
- Mustache Templating for Output: Utilizes a Mustache template (plantuml_er.mustache) to render the parsed JSON model into a human-readable and machine-processable PlantUML diagram format, including descriptions from SQL comments.
- Orchestration and Integration: A shell script (plantuml_er_generate.sh) orchestrates the parsing, model generation, and PlantUML rendering, with an optional step to generate PNG images. A separate validate_schema.sh script provides a dedicated validation entry point.
- Enhanced Documentation: A new doc/plans/er_diagram_codegen.md document outlines the objective, design principles, architecture, components, and implementation steps of the ER diagram generation system.
- SQL Schema Descriptions: Added descriptive comments to 22 existing SQL table definitions (projects/ores.sql/create/**/*.sql) to enrich the generated ER diagram with meaningful context.
COMPLETED Add "words" to icons code
To make the toolbar more readable, it would be nice if we could add some words to icons such as the icons for export and import:
- CSV
- ORE
- FPML
Then we could use 2 well-defined icons for import and export across the code-base.
COMPLETED Add mapping artefact to population functions code
At present this is hard-coded.
COMPLETED Add a ORE component for import/export code
As per FPML analysis, it is better to have all of the export/import code in one place rather than scattered across other components. Add a component specific to ORE.
- Create component
This pull request establishes the groundwork for ORE (Open Source Risk Engine) data handling within the system. It introduces a dedicated ores.ore component, complete with its directory structure, CMake build configurations, and initial code stubs. The changes also ensure that the system's architectural documentation is up-to-date with the new component's presence and purpose, laying a solid foundation for future development of ORE import and export capabilities.
Highlights:
- New Component Introduction: A new component, ores.ore, has been added to the project, providing foundational structure for ORE (Open Source Risk Engine) specific import/export functionality.
- Build System Integration: The new ores.ore component is fully integrated into the CMake build system, including its source, modeling, and testing subdirectories.
- Documentation Updates: The system's architectural documentation, including PlantUML diagrams and the system model, has been updated to reflect the inclusion and details of the new ores.ore component.
- Initial Stub Implementation: Basic stub files for domain logic and testing have been created to ensure the component compiles and integrates correctly from the outset.
COMPLETED Fix windows CI break due to XSD code generation code
This pull request provides a crucial fix for Windows MSVC builds by addressing a specific compilation error. It ensures the project's compatibility and successful compilation on the Windows platform, particularly when dealing with code that generates large object files due to complex template structures.
Highlights:
- MSVC Build Fix: Resolves a C1128 build failure on Windows when compiling domain_xsd.hpp with MSVC.
- Compiler Option Addition: Introduces the /bigobj compiler option to the ores.ore target specifically for MSVC builds.
- Large Object File Support: This option increases the section limit, accommodating large object files often generated due to extensive template usage.
COMPLETED Clean up data layers code
At present the population is a bit messy. We need to structure it around layers.
COMPLETED Add rounding type table code
Values:
- Up, Down, Closest, Floor, Ceiling. Maybe none?
Notes:
- Currency should check against these.
- Supply the mapping table to mappers?
Grok:
Your current list covers several of the most commonly used rounding behaviors in applications:
- Up → typically means always round away from zero (positive direction) — also called Round Up / Towards +∞ / Ceiling-like but always positive direction
- Down → always round toward zero (truncation) — also called Round Down / Truncation / Towards 0
- Closest → round to nearest (with some tie-breaking rule — usually unspecified/default in casual UIs)
- Floor → round down toward −∞ (always toward more negative)
- Ceiling → round up toward +∞ (always toward more positive)
These are already very solid for most general-purpose apps. However, depending on your audience (especially finance, accounting, statistics, or scientific users), you are likely missing one or two very frequently requested/expected options.
### Commonly missing but important ones to consider adding
Bankers (or Banker's Rounding / Round Half Even / Round Half to Even) → Round to nearest, but ties (exactly .5) round to the nearest even digit. This is the statistically unbiased method, required or strongly preferred in:
- Financial applications (interest calculations, totals)
- Many accounting systems
- IEEE 754 default for binary floating-point
- Java BigDecimal.HALF_EVEN, .NET MidpointRounding.ToEven, Python round(), SQL ROUND() in many databases
Very commonly expected when users see "Closest" is not enough.
Half Up (or Round Half Away from Zero / Commercial Rounding) → Round to nearest, ties (.5) always round away from zero (2.5 → 3, -2.5 → -3) This is what most people intuitively think "normal rounding" means in school and is the most common tie-breaking rule in non-financial UIs.
Many users expect this when they choose "Closest".
### Less common but occasionally requested
- Half Down — ties round toward zero (2.5 → 2, -2.5 → -2) — rare in business apps
- Half Toward Zero — same as Half Down
- Half Away from Zero — same as Half Up
- Half to Odd — ties round to odd digit (very rare)
### Suggested final list (modern, user-friendly set)
Most applications end up offering roughly these 5–7 options in a dropdown:
- Up (always away from zero / toward +∞ for positive numbers)
- Down (always toward zero / truncation)
- Floor (toward −∞)
- Ceiling (toward +∞)
- Closest / Nearest (usually implies Half Up in simple UIs)
- Half Up (explicitly — very popular)
- Bankers / Round Half Even / Banker's Rounding (critically important for finance/accounting)
A very clean and common 6-item list seen in many tools:
- Up
- Down
- Floor
- Ceiling
- Nearest, Half Up
- Nearest, Half Even (Bankers)
If you want to keep the list very short, adding just Bankers to your current five is already a big improvement for serious users.
FPML via Gemini:
FpML does not use a "Coding Scheme" (like a URL-referenced list) for rounding in the same way it does for Currencies or Business Centers. Instead, it uses a Complex Type called Rounding and a fixed Enumeration for the direction.
Because rounding logic is typically a structural part of a calculation (e.g., how to round a floating rate or a payout amount), it is "baked into" the schema itself rather than being an external lookup table.
- The Rounding Complex Type
To model rounding in your database or XML, you need two pieces of data:
- precision: An integer representing the number of decimal places.
- roundingDirection: A fixed value from the RoundingDirectionEnum.
Allowed Values for roundingDirection:
- Up: Round away from zero (or to the next higher number).
- Down: Round toward zero (truncate).
- Nearest: Standard mathematical rounding (0.5 rounds up).
COMPLETED Add code generation support for domain types SQL code
Now that we got the basic codegen infrastructure working, we need to start code generating the SQL for domain types.
COMPLETED Separate catalog metadata schema from production data code
Refactor the database architecture to separate catalog/metadata tables from production data tables. This resolves a bootstrapping paradox where catalog metadata must exist before provisioning, but provisioning populates the database.
This pull request implements a significant architectural change by dividing the monolithic database schema into logical metadata and production schemas. This separation is designed to streamline data management, improve data governance, and provide a clearer distinction between data used for defining and staging information versus data actively used by applications. The change impacts nearly all SQL files, requiring updates to schema references, function calls, and data population logic to align with the new structure.
Highlights:
- Schema Restructuring: The single ores PostgreSQL schema has been split into two distinct schemas: metadata and production, along with a public schema for shared utilities. This enhances separation of concerns and clarifies data ownership.
- Schema Content Definition: The metadata schema now houses data governance, classification, and staging tables (e.g., dq_*, change_control). The production schema contains operational data consumed by applications (e.g., refdata_*, iam_*, assets_*, geo_*, variability_*, telemetry_*).
- Cross-Schema References and Validation: All SQL scripts, including table creations, triggers, functions, and population logic, have been updated to use schema-qualified names. Foreign key validations and data population functions now correctly reference tables across the new metadata and production schemas.
- ER Diagram Generation Update: The ER diagram generator has been updated to correctly parse and represent the new multi-schema architecture, ensuring visual documentation remains accurate.
- Documentation Updates: Extensive documentation has been added and updated to explain the new schema mental model, key principles of data flow (unidirectional from metadata to production), and clear boundaries of responsibility for each schema.
- Problem Statement
Currently, the following table categories share the same database:
- Catalog metadata:
dq_datasets_tbl,dq_catalogs_tbl,dq_dataset_bundle_tbl,dq_dataset_bundle_member_tbl,dq_dataset_dependencies_tbl - Artefact staging:
dq_*_artefact_tbltables (countries, currencies, images, FPML entities, etc.) - Production data:
refdata_*_tbl,assets_*_tbl, IAM tables
This creates problems:
- Cannot provision a fresh system because catalog definitions don't exist yet.
- Bundle publication requires bundles to be defined before they can be applied.
- Unclear separation between "system configuration" and "user data".
- Catalog metadata:
- Proposed Solution
Evaluate options:
- Separate schemas: Keep catalog metadata in a
dqschema, production inoresschema. Template database includesdqschema pre-populated. - Separate databases: Catalog metadata in a "control plane" database, production in "data plane" database.
- Embedded metadata: Bundle definitions embedded in application code or configuration files rather than database.
- Separate schemas: Keep catalog metadata in a
- Acceptance Criteria
- Clear separation between catalog/metadata and production data.
- Fresh system can be provisioned without chicken-and-egg problem.
- Bundle definitions are available before first provisioning.
- Existing population scripts continue to work.
- System Provisioner Wizard can be implemented.
- Related Stories
- "Add System Provisioner Wizard to Qt" - blocked by this work.
COMPLETED Generate C++ code for ORE code
It seems a bit painful to have to manually craft entities for parsing ORE and FPML code. Explore tooling in this area.
This pull request significantly upgrades the system's data handling capabilities by integrating xsdcpp for automated C++ type generation from XML schemas. This change not only modernizes the way ORE XML types are managed but also enhances the data quality publication process by introducing a dedicated artefact_type mechanism for managing target tables and population functions. Additionally, it standardizes SQL function naming and corrects currency rounding logic, leading to a more robust and maintainable codebase.
Highlights:
- XSDCPP Code Generation Integration: Introduced infrastructure to automatically generate C++ types from XSD schemas using the xsdcpp tool, streamlining the creation and maintenance of domain types for ORE XML configurations.
- Refactored ORE XML Types: Replaced manually crafted CurrencyConfig and CurrencyElement C++ types with automatically generated currencyConfig and currencyDefinition types, improving consistency and reducing manual effort.
- Enhanced Data Quality (DQ) Publication Infrastructure: Added a new artefact_type domain, entity, mapper, and repository to centralize the lookup of target_table and populate_function for dataset publication, removing these fields directly from the dataset entity.
- SQL Naming Convention Enforcement: Renamed all dq_populate_* SQL functions to follow a consistent dq_populate_*_fn suffix convention across the database schema.
- Currency Rounding Type Correction: Fixed invalid currency rounding types in the CURRENCY_DEFAULTS_POOL within generator.py and in SQL populate scripts, changing 'standard' and 'swedish' to 'Closest', and 'none' to 'Down' for commodity currencies.
Links:
- codesynthesis xsd: good but requires their own library at runtime and it's not on vcpg.
- codesynthesis xsde: good but requires their own library at runtime and it's not on vcpg.
- #11: Issues parsing XSD for ORE (Open Source Risk Engine): raised issue against xsdcpp project for ORE schema.
COMPLETED Add dataset bundles code
Group together datasets so that you can just install a bundle and have a system ready to use.
This pull request significantly enhances the data management capabilities by introducing a robust 'Dataset Bundle' feature. This allows for the logical grouping and coordinated publication of multiple datasets, ensuring data consistency and simplifying the deployment of related reference data. The changes encompass new database schema elements, comprehensive PL/pgSQL functions for lifecycle management, and initial seed data to demonstrate its utility, ultimately streamlining the process of setting up and maintaining coherent data environments.
Highlights:
- New Feature: Dataset Bundles: Introduced the concept of 'Dataset Bundles', which are named collections of datasets designed to work together, allowing the system to be brought into a ready state with a coherent set of reference data.
- New Database Objects: Added three new tables: dq_dataset_bundles_tbl (main bundle definition), dq_dataset_bundle_members_tbl (junction table linking bundles to datasets), and dq_bundle_publications_tbl (audit table for bundle publication history).
- Bundle Management Functions: Implemented a suite of PostgreSQL functions for managing dataset bundles, including dq_list_bundles_fn() (list available bundles), dq_list_bundle_datasets_fn() (list datasets within a bundle), dq_preview_bundle_publication_fn() (simulate publication), dq_populate_bundle_fn() (publish all datasets in a bundle), and dq_get_bundle_publication_history_fn() (retrieve publication audit records).
- Automated Bundle Publication: The dq_populate_bundle_fn() function orchestrates the publication of all member datasets within a bundle to production, processing them in a defined display order to respect dependencies and logging individual dataset publication results.
- Seed Data and Upsert Functions: Added upsert_dq_dataset_bundle() and upsert_dq_dataset_bundle_member() functions to facilitate idempotent seeding of bundle definitions and their members, along with initial seed data for 'solvaris', 'base', and 'crypto' bundles.
COMPLETED Fix issues with xsdcpp when generating ORE code code
- Fix issues with xsd tool
This pull request significantly improves the accuracy and completeness of the ores.ore domain model by integrating fixes to the xsdcpp code generation tool. These changes enable the correct representation of complex XML structures, such as trade data types and vector-based model parameters, which in turn allows for more comprehensive and realistic testing using actual ORE sample files. The update addresses critical XSD parsing limitations, moving the project closer to full XSD schema compliance.
Highlights:
- XSD Code Generation Fixes: The xsdcpp tool has been updated to correctly handle xs:group ref expansion, ensuring trade data types (like SwapData, FxForwardData) are properly generated. It also now correctly generates xsd::vector<T> for maxOccurs="unbounded" within xs:choice elements, specifically fixing the LGM generation in InterestRateModels.
- Domain Code Regeneration: The ores.ore domain types have been regenerated, resulting in significant additions to domain.hpp (+10,752 lines) and domain.cpp (+17,459 lines) to incorporate the newly generated trade data types and their serialization logic.
- Enhanced Simulation Tests: Simulation roundtrip tests now utilize real ORE sample XML files, leveraging the fix for LGM cardinality, allowing for more robust testing against actual data.
- Updated Portfolio Tests: Portfolio roundtrip tests have been modified to use inline XML for various trade types, including those with PortfolioIds, as a workaround for the still unsupported XSD substitution groups (NettingSetId).
- Add round-trip tests
This pull request significantly enhances the robustness of the ores.ore library by introducing a suite of XML roundtrip tests. These tests validate the integrity of data serialization and deserialization for key domain objects, ensuring that XML inputs can be correctly parsed into C++ objects and then accurately re-serialized back into XML. Complementing this, the PR delivers a critical analysis of the current XSD-to-C++ code generation process, pinpointing several structural and cardinality mismatches that lead to parsing failures for certain ORE sample XMLs. This dual approach not only improves testing coverage but also provides actionable insights for future improvements to the XML schema and code generation tooling.
Highlights:
- New XML Roundtrip Tests: Added comprehensive structural XML roundtrip tests for various ores.ore domain types, including currencyConfig, conventions, curveconfiguration, todaysmarket, pricingengines, simulation, and portfolio. These tests validate the integrity of data serialization and deserialization.
- XSD Schema Gaps Analysis: Introduced a new analysis document (doc/analysis/ore_xsd_schema_gaps.md) that meticulously details identified discrepancies between ORE sample XML files and the XSD-generated C++ domain code.
- Identified Code Generator Limitations: Documented specific limitations of the xsdcpp code generator, such as its failure to expand xs:group ref, handle xs:element substitutionGroup, and correctly map maxOccurs="unbounded" within xs:choice to xsd::vector.
COMPLETED Add UI for bootstrapping from Qt code
At present we need to go to the shell to bootstrap. It would be easier if we just had a button in Qt for this. Actually we probably need a little wizard which takes you through choosing an initial population etc.
This pull request introduces a crucial user experience improvement by providing a guided, interactive wizard for first-time system initialization. It resolves the 'chicken-and-egg' problem where a new system couldn't be easily set up without an existing administrator account or initial data. The wizard streamlines the process of creating the first admin and populating the system with essential reference data, making the application much more user-friendly upon initial deployment.
Highlights:
- New System Provisioner Wizard: Introduces a multi-page wizard UI (SystemProvisionerWizard) to guide users through the initial setup of a fresh system, including creating an administrator account and selecting an initial data bundle.
- Bootstrap Mode Detection and Handling: The system now detects if it's in 'bootstrap mode' (no administrator account exists). If detected, the LoginDialog emits a signal, and the MainWindow automatically displays the new SystemProvisionerWizard instead of the standard login form.
- Admin Account Creation and Data Provisioning: The wizard facilitates the creation of the initial administrator account with validation for username, email, and password. It also allows users to select a dataset bundle (e.g., Solvaris, Base System, Crypto) for initial data provisioning, with progress tracking and logging.
- Product Backlog Documentation: Two new stories have been added to the product backlog: one detailing the 'System Provisioner Wizard' feature and its acceptance criteria, and another addressing the architectural issue of 'Separating catalog metadata schema from production data' which is a prerequisite for full provisioning functionality.
- Analysis
Some analysis on this via Gemini:
- we should call this "Data Provisioning". The wizard could be the data provisioning wizard.
- way to improve data setup:
Large systems often use a "Vanilla vs. Flavoured" approach:
- The Vanilla Step: This is the Baseline Configuration. It is non-negotiable and contains ISO codes (Currencies/Countries) and FpML schemas.
- The Flavor Step: The user chooses a Vertical or Scenario.
"Apply Financial Services Template?" (Adds FpML specific catalogs).
"Apply IDES/Demo Dataset?" (Adds the fictional entities and trades).
- "Demonstration and Evaluation": it should be possible to load up the system in a way that it is ready to exercise all of it's functionality.
- Merged stories
- Add screen in qt to exit bootstrap mode*
As per claude:
The create_initial_admin_request message type serves several important purposes that differentiate it from the CLI and REPL approaches:
Why We Need create_initial_admin_request
- Network-accessible bootstrap flow
- Allows remote initial setup from localhost without requiring shell/CLI access
to the server
- Enables a web-based "first-run" setup experience (like many web applications)
- The Qt client can provide a proper UI for initial admin account creation
- Localhost-only security enforcement
- The endpoint enforces that it can only be called from localhost (127.0.0.1 or
::1) at line projects/ores.accounts/src/messaging/accounts_message_handler.cpp:320
- Provides network-accessible bootstrap with security guarantees
- Prevents remote bootstrap attacks
- Atomic mode transition
- The endpoint both creates the admin AND exits bootstrap mode in a single atomic operation (lines 362-367 in accounts_message_handler.cpp)
- Guarantees consistency - can't create admin without exiting bootstrap mode
- Service-layer validation
- Goes through full service layer with password validation and business logic
- The CLI is essentially an "administrative backdoor" that bypasses the service
layer and writes directly to the database
- Protocol-compliant workflow
- Clients speaking the binary protocol need a proper bootstrap endpoint
- REPL create_account_request is blocked in bootstrap mode (by enforcement logic)
- create_initial_admin_request is the only endpoint that works in bootstrap mode
The Distinction
- CLI approach: Administrative backdoor, direct database access, bypasses all
service logic
- create_initial_admin_request: Proper network-accessible bootstrap flow with
localhost restriction and atomic mode transition
- REPL create_account_request: Normal account creation, blocked in bootstrap mode
The create_initial_admin_request enables a proper "first-run experience" for clients connecting via the network protocol, while maintaining security through localhost-only access.
- Add System Provisioner Wizard to Qt code
Create a
SystemProvisionerWizardin ores.qt to guide users through first-time system initialization. The wizard provisions the system layer-by-layer, culminating in a fully operational deployment.- Background
During system bootstrap, users need to:
- Create the initial administrator account.
- Provision the Foundation layer (change reasons, IAM permissions/roles, etc.).
- Provision the Data Governance layer (dimensions, methodologies, artefact types).
- Provision the Data Catalogues layer (catalogs, datasets, artefact data).
- Publish selected bundles to Production.
- Wizard Structure (Option A: Technical/Layer-Aligned)
Page Name Purpose 1 AdminAccountPage Create initial admin (username, email, password) 2 FoundationLayerPage Select bundle(s) for foundation (mandatory) 3 DataGovernanceLayerPage Select bundle(s) for governance (mandatory) 4 DataCataloguesLayerPage Select bundle(s) for catalogues (optional) 5 ProvisioningPage Execute all selections, show progress - Bundle Selection Behavior
- Each layer page displays available bundles with descriptions.
- Some layers have a single mandatory bundle (Foundation, Data Governance).
- Some layers allow "leave empty" (Data Catalogues, Production).
- Selections are collected per-page but applied transactionally at the end.
- The final page executes all provisioning and shows per-layer progress.
- Architectural Issue Identified
The current database design places catalog metadata (
dq_datasets_tbl,dq_catalogs_tbl,dq_dataset_bundle_tbl, etc.) in the same database as production data. This creates a bootstrapping paradox: the catalog metadata must exist before provisioning can occur, but provisioning is supposed to populate the database. - Dependencies
- Prerequisite: Refactor database to separate catalog/metadata schema from production data schema. This is blocking work for the wizard.
- Server-side: Infrastructure to apply bundles transactionally is not yet implemented. Need bundle application endpoints/services.
- Related story: "Add screen in qt to exit bootstrap mode" - the wizard subsumes this functionality.
- Related story: "Make bootstrap operation atomic using SQL transactions" - same transactional pattern applies.
- ERP Terminology Mapping
ORES Layer ERP Equivalent Foundation System Configuration / Core Setup Data Governance Master Data Governance / Data Stewardship Data Catalogues Master Data / Reference Data Import Production (Publish) Go-Live / Data Activation - Acceptance Criteria
- Wizard only appears when system is in bootstrap mode.
- Admin account creation follows existing
create_initial_admin_requestpattern. - Each layer page shows clear description of layer purpose.
- Bundle selection is intuitive with mandatory/optional indicators.
- Provisioning is transactional (all-or-nothing).
- Progress is visible per-layer during execution.
- System exits bootstrap mode upon successful completion.
- Wizard is first-time only (not re-runnable).
- Background
- Add screen in qt to exit bootstrap mode*
COMPLETED Fix code review comments for librarian code
We ran out of tokens to address code review comments from:
Notes:
- cannot view domains, edit etc. Done.
- consider adding nodes to the tree with like dimensions so that users effectively can filter by those. Done.
- check to see if the diagram is using the new message to retrieve dependencies. Done.
- most countries don't seem to have flags. How and when is the mapping done? actually after a restart I can now see the flags. It seems we need to force a load. Done.
- headers in data set are the same colour as rows. Make them different.
- crypto currencies sometimes overlap with countries and iso currencies. we should "namespace" them somehow to avoid having a country flag being overwritten by a crypto icon (happens with AE).
- when publish fails we can't see the errors. Raised story.
POSTPONED Add FPML export and import code
Where we can, we should start to add export and import functionality for FPML. This validates our modeling and catches aspects we may be missing.
Currency export:
<?xml version="1.0" encoding="utf-8"?> <referenceDataNotification xmlns="http://www.fpml.org/FpML-5/reporting" fpmlVersion="5-11"> <header> <messageId messageIdScheme="http://sys-a.gigabank.com/msg-id">SYNC-CURR-2026-001</messageId> <sentBy>GIGABANK_LEI_A</sentBy> <creationTimestamp>2026-01-25T10:00:00Z</creationTimestamp> </header> <currency> <currency currencyScheme="http://www.fpml.org/coding-scheme/external/iso4217">USD</currency> </currency> <currency> <currency currencyScheme="http://www.fpml.org/coding-scheme/external/iso4217">EUR</currency> </currency> </referenceDataNotification>
and:
<header> <messageId messageIdScheme="http://instance-a.internal/scheme">MSG_99821</messageId> <sentBy>INSTANCE_A</sentBy> <creationTimestamp>2026-01-25T14:30:00Z</creationTimestamp> </header>
- Create component
We need a component to place all of the common infrastructure. As per Gemini analysis:
To achieve FpML schema validation using libxml2, you need to treat the FpML schemas as a "Black Box" of rules. Since FpML is highly modular, you don't just validate against one file; you validate against a "Root" schema that imports the others.
Here is the most efficient path to implementing XML validation for your Identity Layer.
- Download the "Reporting" Schema Set
FpML is divided into "Views." For party and business unit data, you want the Reporting View.
- Go to FpML.org Download Section.
- Download the Reporting View Zip.
- Locate fpml-main-5-11.xsd. This is your entry point.
- The "Schema Repository" Pattern
Libxml2 requires all imported .xsd files to be reachable.
Place the downloaded XSDs in a folder (e.g., schemas/fpml-5-11).
In your code, you will point the xmlSchemaNewParserCtxt to the main file. Libxml2 will automatically follow the <xsd:import> tags to the other files in that directory.
- Creating a "Wrapper" for Partial Validation
FpML schemas are designed to validate full messages (like a Trade Notification), not just a standalone party table row. To validate just your parties, you have two choices:
Option A: The "Fragment" Approach (Easiest for testing)
Construct a minimal, valid FpML "Party Notification" message in memory that wraps your data.
XML <partyNotification xmlns="http://www.fpml.org/FpML-5/reporting"> <header> <messageId messageIdScheme="http://yourbank.com/msg-id">MSG001</messageId> <sentBy>YOURBANK_LEI</sentBy> <sendTo>VALIDATOR</sendTo> <creationTimestamp>2026-01-23T09:00:00Z</creationTimestamp> </header> <party> <partyId partyIdScheme="http://www.fpml.org/coding-scheme/external/iso17442">549300V5E66A3S316907</partyId> <partyName>GigaBank PLC</partyName> </party> </partyNotification>
These common components should go into
ores.fpml. We then need to figure out how to organise the exporters.This pull request introduces a new 'ores.fpml' component, designed to handle Financial Products Markup Language operations, complete with its basic structure for source code, tests, and modeling. Concurrently, it updates the 'Component Creator' skill guide documentation to ensure it accurately reflects the latest logging system architecture, providing clear instructions for integrating logging functionality and resolving potential compilation issues for new components.
Highlights:
- New ores.fpml Component: A new component for Financial Products Markup Language (FPML) operations has been added, including its source, tests, and modeling setup.
- Documentation Update for Logging: The 'Component Creator' skill guide documentation has been updated to reflect current logging system changes, specifically regarding the 'ores.logging.lib' dependency and the 'ores::logging' namespace.
- CMake Configuration for New Component: The main 'projects/CMakeLists.txt' has been updated to include the new 'ores.fpml' component, and its own CMake files are set up for building the library, tests, and PlantUML diagrams.
POSTPONED Base the compute approach on BOINC code
Copy the BOINC data model.
- Analysis work with Gemini
- Description: As a QuantDev team, we want to build a distributed compute grid to execute high-performance financial models (ORE, Ledger, LLM) across multiple locations. We will use PostgreSQL as the central orchestrator, leveraging PGMQ for task delivery and TimescaleDB for result telemetry.
- Architectural Components (BOINC Lexicon)
- Host (Node): The persistent infrastructure service running on the hardware. It manages system resources and the lifecycle of task slots.
- Wrapper: A transient, task-specific supervisor that manages the environment, fetches data via URIs, and monitors the engine.
- App Executable (Application): The core calculation engine (e.g., ORE Studio, llama.cpp) executed by the Wrapper.
- Workunit: The abstract definition of a problem, containing pointers to input data and configurations.
- Result: A specific instance of a Workunit assigned to a Host.
- Technical Stack:
- Database: PostgreSQL (Central State Machine).
- Queueing: PGMQ (for "Hot" result dispatching).
- Time-Series: TimescaleDB (for node metrics and assimilated financial outputs).
- Storage: Postgres with BYTEA column (for zipped input/output bundles). Let's stick with this sub-optimal approach until we hit some resource issues.
- Communication: Server Pool (Load-balanced API) to buffer nodes from the database.
To provide a robust, strictly-typed orchestration layer, we must implement the following entities within the PostgreSQL instance.
- 1. The Host (Node) Entity
Represents the physical or virtual compute resource.
Table:
hostsid: UUID (Primary Key).external_id: TEXT (User-defined name/hostname).location_id: INTEGER (FK to site/region table).cpu_count: INTEGER (Total logical cores).ram_mb: BIGINT (Total system memory).gpu_type: TEXT (e.g., 'A100', 'None').last_rpc_time: TIMESTAMPTZ (Last heartbeat from the Node).credit_total: NUMERIC (Total work units successfully processed).
- 2. The Application & Versioning (App Executable)
Defines the "What" – the engine being wrapped.
Table:
appsid: SERIAL (PK).name: TEXT (e.g., 'ORE_STUDIO').- Table:
app_versions id: SERIAL (PK).app_id: INTEGER (FK).wrapper_version: TEXT (Version of our custom wrapper).engine_version: TEXT (Version of the third-party binary).package_uri: TEXT (Location of the zipped Wrapper + App bundle).platform: TEXT (e.g., 'linux_x86_64').
- 3. The Workunit (Job Template)
The abstract problem definition. Does not contain results.
Table:
workunitsid: SERIAL (PK).batch_id: INTEGER (FK).app_version_id: INTEGER (FK).input_uri: TEXT (Pointer to zipped financial data/parameters).config_uri: TEXT (Pointer to ORE/Llama XML/JSON config).priority: INTEGER (Higher = sooner).target_redundancy: INTEGER (Default: 1. Set > 1 for volunteer/untrusted nodes).canonical_result_id: INTEGER (Nullable; updated by Validator).
- 4. The Result (Execution Instance)
The bridge between the DB and PGMQ.
Table:
resultsid: SERIAL (PK).workunit_id: INTEGER (FK).host_id: INTEGER (FK, Nullable until dispatched).pgmq_msg_id: BIGINT (The lease ID from PGMQ).server_state: INTEGER (1: Inactive, 2: Unsent, 4: In Progress, 5: Done).outcome: INTEGER (Status code: Success, Compute Error, Timeout).output_uri: TEXT (Where the Wrapper uploaded the result zip).received_at: TIMESTAMPTZ.
- 5. The Batch & Assimilator State
Handles the finance-specific "Batch" requirement and dependencies.
Table:
batchesid: SERIAL (PK).external_ref: TEXT (Link to Finance UI/Project ID).status: TEXT (Open, Processing, Assimilating, Closed).
Table:
batch_dependenciesparent_batch_id: INTEGER (FK).child_batch_id: INTEGER (FK).
Table:
assimilated_data(TimescaleDB Hypertable)time: TIMESTAMPTZ (Logical time of financial observation).batch_id: INTEGER (FK).metric_key: TEXT (e.g., 'portfolio_var').metric_value: NUMERIC.
- Notes
- Schema must enforce that a
Resultcannot be marked 'Success' without a validoutput_uri. - The
batch_statemust be dynamically computable via a view or updated via trigger to show % completion. - The
app_versionstable must support "side-by-side" versions for A/B testing risk engines.
- Schema must enforce that a
- Links
Footer
| Previous: Version Zero |