Sprint Backlog 11
Sprint Mission
- Add multi-tenant support.
Stories
Active
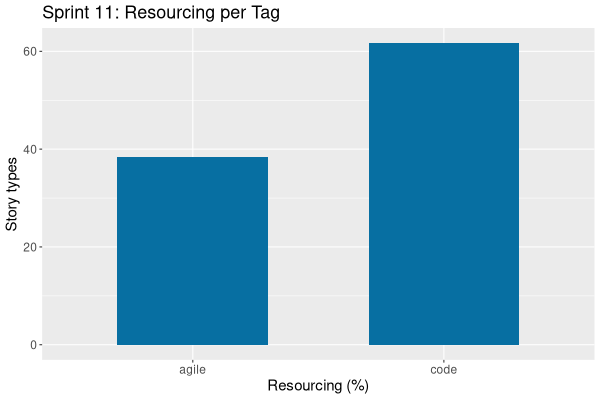
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 11:32 | 100.0 | |||
| Stories | 11:32 | 100.0 | |||
| Active | 11:32 | 100.0 | |||
| agile | Sprint and product backlog refinement | 0:11 | 1.6 | ||
| code | Refactor message handlers for per-request tenant context | 1:48 | 15.6 | ||
| analysis | Review DQ metadata tables for multi-tenancy support | 1:41 | 14.6 | ||
| code | vcpkg is still not caching correctly | 1:25 | 12.3 | ||
| code | Check that data librarian can publish across tenants | 2:51 | 24.7 | ||
| code | Check that eventing works correctly across tenants | 3:36 | 31.2 |
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 72:58 | 100.0 | |||
| Stories | 72:58 | 100.0 | |||
| Active | 72:58 | 100.0 | |||
| agile | Sprint and product backlog refinement | 2:35 | 3.5 | ||
| code | Address past review comments | 1:14 | 1.7 | ||
| code | Split "god" admin account | 10:05 | 13.8 | ||
| code | Move all database entities to public schema | 1:22 | 1.9 | ||
| code | Check directory structure in SQL | 0:36 | 0.8 | ||
| code | Add tenancy support | 3:55 | 5.4 | ||
| code | Use tenancy to isolate tests | 5:00 | 6.9 | ||
| code | Add NOTICE logging support to sqlgen | 0:53 | 1.2 | ||
| code | Update codegen for tenancy | 3:32 | 4.8 | ||
| code | Add entity types for tenants | 9:43 | 13.3 | ||
| code | Add sink to log to database directly | 5:00 | 6.9 | ||
| code | Add system accounts for services | 3:32 | 4.8 | ||
| code | Test shell functionality with tenancy enabled | 9:44 | 13.3 | ||
| code | Fix apt-get failures on nightly build | 0:20 | 0.5 | ||
| code | Refactor tenant lookup functions to accept const context | 0:58 | 1.3 | ||
| code | Refactor message handlers for per-request tenant context | 4:56 | 6.8 | ||
| analysis | Review DQ metadata tables for multi-tenancy support | 1:41 | 2.3 | ||
| code | vcpkg is still not caching correctly | 1:25 | 1.9 | ||
| code | Check that data librarian can publish across tenants | 2:51 | 3.9 | ||
| code | Check that eventing works correctly across tenants | 3:36 | 4.9 |
COMPLETED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
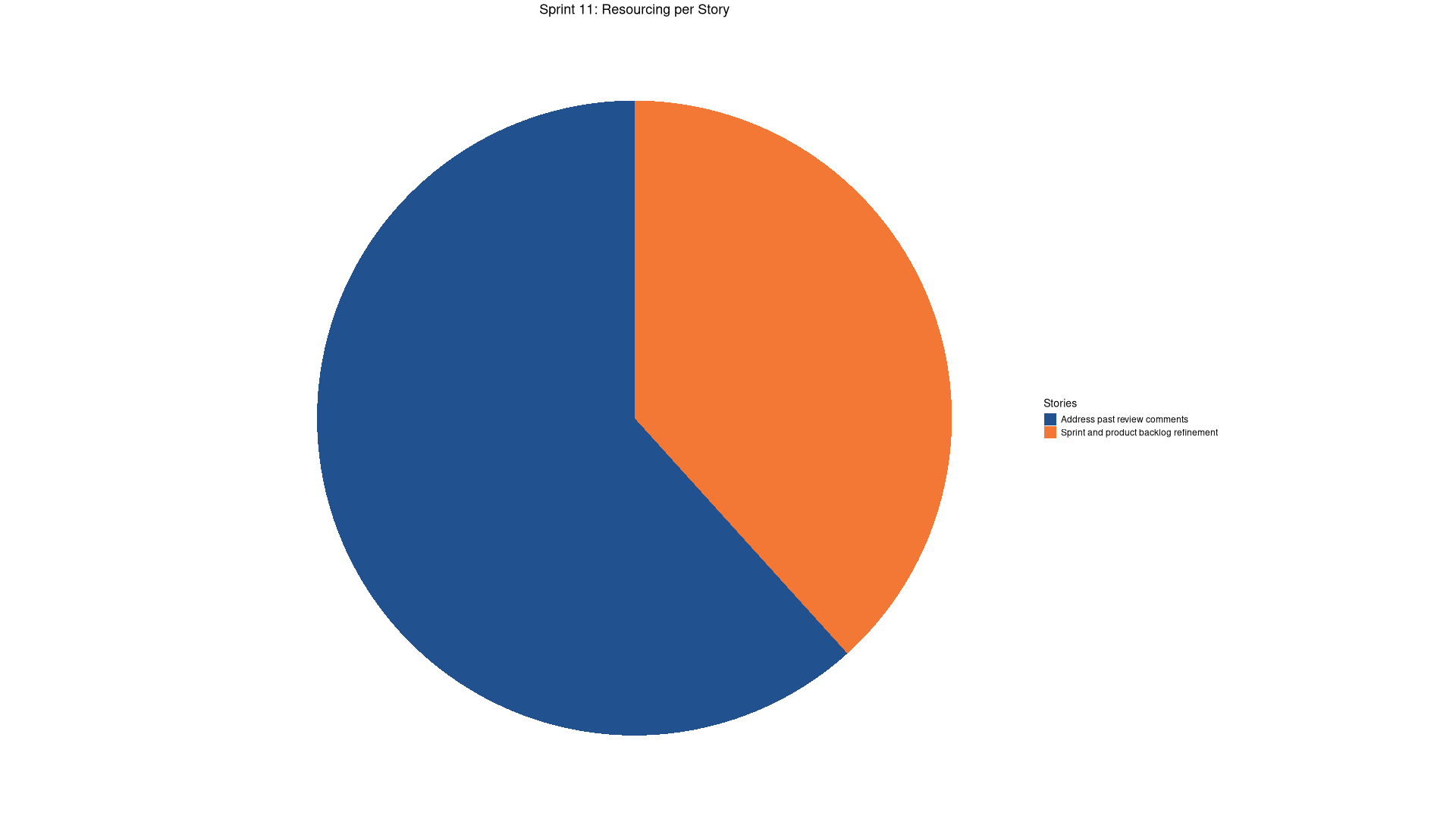
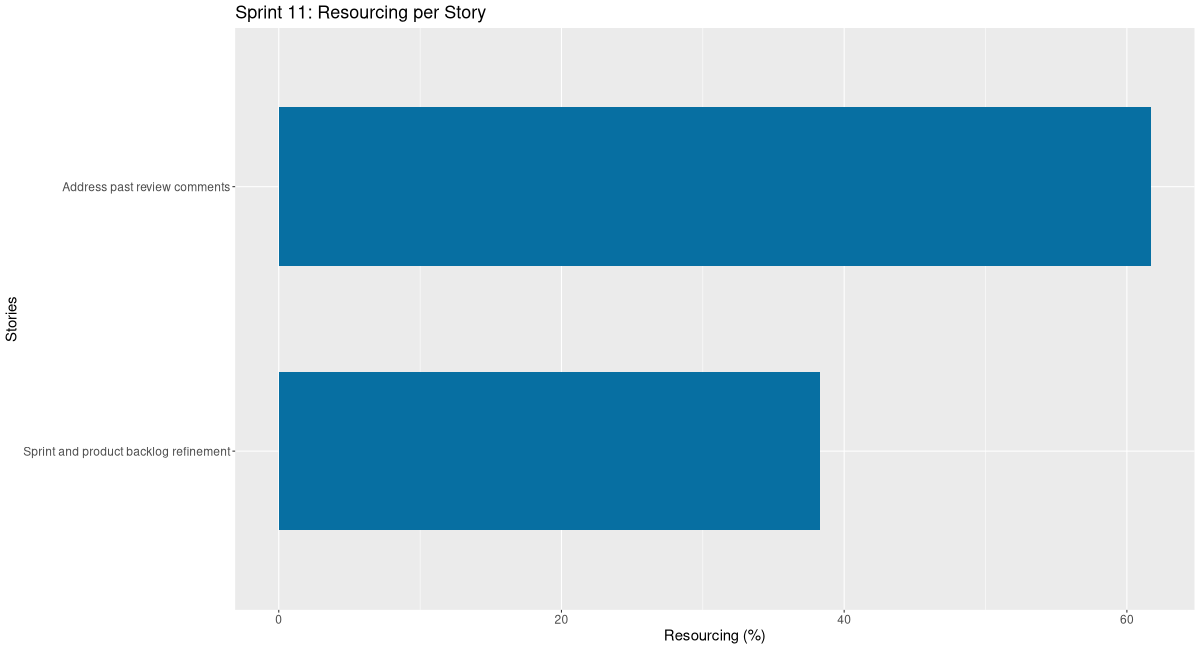
COMPLETED Address past review comments code
We have a number of comments we did not address from past PRs. PRs:
This pull request focuses on addressing various code review feedback points and performing general maintenance across the Qt, DQ, and ORE components. The changes aim to improve UI robustness, enhance code maintainability through refactoring and dependency management, and provide more informative user feedback, ultimately contributing to a more stable and user-friendly application. The updates also include minor documentation clean-up and copyright year adjustments.
Highlights:
- Qt Component Enhancements: Multiple MDI windows (ChangeReasonCategory, ChangeReason, Country, Currency, DataLibrarian, DatasetBundle, OriginDimension) now robustly restore their header states. If saved settings are corrupted, they gracefully fall back to default column visibility, preventing potential UI issues. The DataLibrarianWindow::getDatasetsUnderNode method has been optimized to efficiently handle root and category parent nodes, avoiding redundant dataset iterations and ensuring unique entries. Validation feedback for dataset bundles is more specific, pinpointing missing required fields. Batch deletion error messages for dataset bundles now include the codes of failed bundles and their specific failure reasons, improving user clarity. Lambda capture ordering in DatasetBundleController has been adjusted for better readability.
- DQ Component Refactoring: The write_dataset and read_dataset serialization helpers have been extracted from an anonymous namespace in dataset_protocol.cpp and exposed in dataset_protocol.hpp. This change promotes code reuse, eliminating approximately 200 lines of duplicated serialization logic previously found in publication_protocol.cpp.
- ORE Component Maintenance: CMake dependencies for the ORE library (projects/ores.ore/src/CMakeLists.txt) have been updated to align with actual code usage and the architecture diagram. This involved removing unused dependencies (e.g., ores.variability.lib, ores.comms.lib, sqlgen::sqlgen, faker-cxx::faker-cxx, libfort::fort) and adding required ones (ores.logging.lib, ores.platform.lib). The copyright year in projects/ores.ore/tests/CMakeLists.txt has been updated from 2024 to 2025.
- Documentation Updates: The doc/agile/product_backlog.org file has been significantly pruned, removing numerous outdated or completed backlog items. The doc/agile/v0/sprint_backlog_11.org file has been updated to reflect current clock summaries and the status of a sprint backlog item.
COMPLETED Split "god" admin account code
We are using a single account with all the rights. This is not a good idea.
Analysis by Gemini:
Moving away from a single "god user" is a classic architectural glow-up. Your plan aligns well with the **Principle of Least Privilege (PoLP)** and standard PostgreSQL security patterns. In the Postgres ecosystem, this is often referred to as **Role-Based Access Control (RBAC)**. Here is a breakdown of your proposal and how to refine it to match industry "best practices." --- ### 1. Refined Role Hierarchy Instead of managing permissions for every single service user individually, most Postgres pros use **Group Roles**. You create "nologin" roles that hold the permissions, and then your service users "inherit" those permissions. | Role Type | Name (Example) | Purpose | | --- | --- | --- | | **Owner (DDL)** | `ores_owner` | Owns all tables/schemas. Used for migrations. | | **Read/Write (DML)** | `ores_rw` | Group role with `SELECT`, `INSERT`, `UPDATE`, `DELETE`. | | **Read Only (RO)** | `ores_ro` | Group role with only `SELECT`. Great for analytics/debugging. | | **Service Users** | `ores_http_user` | These roles have `LOGIN` and belong to `ores_rw` or `ores_ro`. | --- ### 2. Feedback on Your Specific Categories #### **Application Service Users** Your breakdown (`cli`, `wt`, `comms`, `http`) is excellent for **auditability**. If you see a spike in slow queries, you’ll know exactly which service is the culprit. **Pro Tip:** Ensure these users do not own the tables they write to. If a service user creates a table, the `ores_ddl_user` might not be able to modify it later without a `REASSIGN OWNED` command. #### **The DDL User (The Migrator)** In Postgres, the most idiomatic way is to make this user the **Owner** of the schema. **Why?** Only the owner (or a superuser) can perform `ALTER TABLE` or `DROP INDEX`. **Safety:** Your CI/CD pipeline should use this user, but your application code should **never** have these credentials. #### **Read-Only & Admin Roles** - **Read-Only:**: This is non-negotiable for production. Give it to your BI tools (Metabase, Tableau) or developers who need to run manual `SELECT` queries to troubleshoot. - **Admin User:**: Usually, the cloud provider (like RDS or GCP) gives you a `postgres` or `cloudsqladmin` user. You rarely need to create a custom one unless you have a dedicated DBA team. --- ### 3. Implementation Gotchas Postgres permissions can be "sticky." Keep these two things in mind: 1. **Default Privileges:** By default, when `ores_ddl_user` creates a new table, `ores_http_user` won't have access to it unless you use: ```sql ALTER DEFAULT PRIVILEGES FOR ROLE ores_ddl_user IN SCHEMA public GRANT SELECT, INSERT, UPDATE ON TABLES TO ores_rw; ``` 2. **Schema Ownership:** Keep the `public` schema (or your custom schema) owned by your DDL user. --- ### 4. Summary Verdict Your approach is **solid and highly recommended**. It prevents a vulnerability in your `http` service from being used to `DROP TABLE`, and it makes your logs much more readable.
COMPLETED Remove postgres passwords from github workflows code
Rationale: done as part of the ores user split.
As a quick hack we added the dev passwords to the workflows. We should really generate these on the fly and supply them to the tests.
COMPLETED Move all database entities to public schema code
Gemini:
## The Agile Story: The Burden of the "Clean" Wall
### 1. The Starting Point: The "Two-Room" Architecture
We initially separated our database into two schemas: Metadata and Production. We did this for "cleanliness"—believing that physical walls would make the system easier to navigate.
### 2. The Friction (The "Blockers")
As our feature set grew, we encountered three main "Agile anti-patterns":
- The Search-Path Tax: Every time a developer wrote a query, they had to manage the `search_path` or use long-winded prefixes (e.g., `metadata.system_config JOIN production.ores_iam_accounts`). This added cognitive load and slowed down every PR.
- The Catalog Bottleneck: PostgreSQL's internal brain (the catalog) had to work harder to resolve table locations across multiple namespaces.
- Deployment Fragility: Our CI/CD pipelines became complex. We had to ensure schemas were created in the exact right order, or our foreign key constraints would fail during migration.
### 3. The Pivot: Moving to the "Unified Grand Hall"
We decided to adopt the Odoo-style Namespacing approach. We tore down the schema walls and moved everything into the `public` schema, but with a strict, tiered naming convention: `ores_iam_accounts`.
### 4. The Result (The "Definition of Done")
By consolidating into one schema, we achieved:
- Higher Velocity: Joins are now simple and "local." No more prefixing every table name in the code.
- Natural Organization: Because we use the `ores_` prefix, our 2,000+ tables aren't a mess; they are auto-alphabetized. All IAM tables sit together, all Financial tables sit together.
- Standardized Tooling: Every standard PostgreSQL tool, backup script, and ORM works better with a single schema. We stopped fighting the tools and started using them as intended.
—
### The Executive Summary
> "We traded the illusion of cleanliness for the reality of speed." > By moving to a single schema with prefixes, we kept the organizational benefits of schemas without the operational debt of cross-schema management.
COMPLETED Check directory structure in SQL code
- why is there a projects/ores.sql/create/change_control directory.
- why are these dq?
projects/ores.sql/create/refdata/dq_account_types_artefact_create.sql
This pull request significantly refactors the ores.sql project's file structure and naming conventions. The primary goal is to enhance clarity, consistency, and maintainability by standardizing SQL file names, consolidating data governance scripts into a single dq directory, and removing numerous orphaned reference data files. These changes improve the overall organization and reduce redundancy within the SQL codebase.
Highlights:
- Standardized SQL File Naming: All SQL files now consistently use a [name]_[purpose].sql suffix pattern (e.g., iam_create.sql instead of create_iam.sql) for improved clarity and consistency.
- Consolidated Data Governance: The change_control/ directory has been merged into the dq/ directory, centralizing data quality and governance-related SQL scripts.
- Removed Orphaned Reference Data Files: Approximately 45 duplicate or unused SQL files related to reference data (refdata/) have been removed, streamlining the codebase.
- Sprint Backlog Updates: The sprint backlog was updated, marking 'Move all database entities to public schema' and 'Check directory structure in SQL' as completed.
COMPLETED Add tenancy support code
Do some analysis and prototyping around supporting multiple tenants on a single database.
- Initial tenant setup
This pull request lays the foundational groundwork for multi-tenancy within the SQL schema. It systematically integrates tenant identification into the database structure, ensuring that data is logically separated and managed on a per-tenant basis. The changes span across table definitions, indexing strategies, data validation logic, and data population scripts, providing a robust and scalable solution for supporting multiple isolated client environments.
Highlights:
- Multi-Tenancy Core Infrastructure: Introduced new tables: 'ores_iam_tenant_types_tbl' for tenant classifications, 'ores_iam_tenant_statuses_tbl' for lifecycle states, and 'ores_iam_tenants_tbl' as the central tenant management table, complete with bitemporal support.
- Tenant-Aware Schema Modifications: Added a 'tenant_id' column to approximately 70 existing entity tables across various modules (assets, data quality, geo, IAM, refdata, telemetry, variability) to enable tenant-specific data partitioning.
- Enhanced Data Integrity and Uniqueness: Updated unique indexes and constraints on numerous tables to include 'tenant_id', ensuring uniqueness of records within each tenant rather than globally. New 'tenant_id' indexes were also added for improved query performance.
- Automated Tenant Validation: Modified all relevant insert triggers to automatically validate the 'tenant_id' using a new 'ores_iam_validate_tenant_fn' function, preventing data insertion for invalid or inactive tenants.
- Updated Upsert Functions: Adjusted all upsert functions to accept 'tenant_id' as the first parameter, ensuring that seed data and new records are correctly associated with a specific tenant.
- System Tenant and Administrative Roles: Implemented a special 'system' tenant (with a well-known UUID) for platform-level governance data and administration. New 'SuperAdmin' and 'TenantAdmin' roles were introduced with appropriate tenant management permissions.
- Tenant-Specific Session Management: Added functions to retrieve the current session's 'tenant_id' and to look up tenants by hostname, facilitating tenant context management during user sessions.
- Tenancy and seeding
This pull request systematically modifies all database population scripts to enforce multi-tenancy at the data seeding level. By introducing a system tenant ID to every upsert operation, it guarantees that foundational data, such as reference data, configurations, and metadata, is correctly scoped to the system tenant. This is a fundamental architectural adjustment that supports the ongoing development of a robust multi-tenant environment, ensuring data integrity and isolation from the ground up.
Highlights:
- Multi-tenancy Support: All populate scripts have been updated to include ores_iam_system_tenant_id_fn() as the first parameter in upsert function calls, ensuring seeded data is associated with the system tenant.
- Data Association: This change is crucial for correctly scoping foundational data (reference data, configurations, metadata) to the system tenant, supporting a robust multi-tenant environment.
- Project Continuity: This pull request represents the second phase of a broader multi-tenancy implementation, building upon previous work in PR [sql] Add tenant infrastructure and tenant_id to all tables #395.
- Tenancy, login and tests
This pull request significantly enhances multi-tenancy support by automating the assignment of tenant_id for login and session information based on the current session context. It refines the tenant validation logic to be more robust when a tenant ID is not explicitly provided, ensuring data integrity across tenants. Additionally, it establishes a foundational testing framework by setting default tenant contexts for test users and providing a C++ utility to manage this context, which is crucial for transparently integrating existing C++ code with the new multi-tenancy architecture.
Highlights:
- Automatic Tenant ID Population: Added BEFORE INSERT triggers to iam_login_info_tbl and iam_sessions_tbl to automatically populate the tenant_id from the session variable (app.current_tenant_id) if it's not explicitly provided during an insert operation. This ensures multi-tenancy context is maintained for these critical tables.
- Enhanced Tenant Validation Function: Modified the ores_iam_validate_tenant_fn to use coalesce(p_tenant_id, ores_iam_current_tenant_id_fn()). This change allows the function to accept a NULL p_tenant_id and gracefully fall back to using the tenant_id set in the current session, improving flexibility and reducing explicit tenant_id passing.
- Default Tenant Context for Test Users: Configured the ores_test_ddl_user and ores_test_dml_user roles in setup_template.sql to have a default app.current_tenant_id set to the system tenant UUID (00000000-0000-0000-0000-000000000000). This simplifies testing by providing a consistent tenant context for these roles.
- Test Infrastructure for Tenant Context: Introduced a new public method set_system_tenant_context() in the database_helper C++ class. This method programmatically sets the app.current_tenant_id session variable to the system tenant UUID, and is now called in the database_helper constructor, streamlining multi-tenancy setup for tests
COMPLETED Use tenancy to isolate tests code
Now that we have tenancy support, a good way to isolate tests is to create tenants. This has many advantages:
- we can use the same database for multiple test suites.
- we can check the results of the tests after running them to validate expectations
- it is faster than destroying databases.
- it is a more realistic test.
Notes:
- we need to ensure we destroy the tenant for a test suite to make sure the test starts with a clean slate.
- Use tenancy in tests
This pull request introduces comprehensive multi-tenancy support across the application's database and testing infrastructure. It establishes a centralized C++ service for managing tenant context, integrates tenant-aware logic into the CLI, and significantly enhances test isolation by provisioning unique tenants for each test run. Furthermore, it refines database RLS policies to accommodate system-level administrative access and provides SQL functions for tenant lifecycle management, ensuring data separation and operational flexibility in a multi-tenant environment.
Highlights:
- Centralized Tenant Context Service: Introduced a new tenant_context C++ service in ores.database to centralize the management of multi-tenant context across all application components. This service allows setting the current tenant via code or UUID and provides utilities for tenant lookup.
- Multi-Tenant Test Isolation: Implemented robust multi-tenant test isolation within the C++ test infrastructure. Each test run now provisions a unique, isolated tenant, including copies of necessary reference data, and deprovisions it upon completion, ensuring clean and independent test environments.
- Enhanced Row-Level Security (RLS) Policies: Updated all existing RLS policies across assets, dq, iam, refdata, telemetry, and variability schemas to explicitly allow the 'system' tenant (UUID 00000000-0000-0000-0000-000000000000) to access all tenant data for administrative and provisioning operations.
- CLI and Environment Variable Tenant Support: Added a –tenant command-line option to the ores.cli application and support for the ORES_TENANT environment variable, allowing users to specify the desired tenant context for CLI operations.
- psqlrc Enhancements for Tenant Management: Modified the psqlrc.sql configuration to automatically set the system tenant context on load, display the current tenant in the psql prompt, and introduced new macros (:tenant, :tenants) for convenient tenant inspection and listing.
- SQL Tenant Provisioning and Deprovisioning Functions: Added SQL functions ores_iam_provision_tenant_fn and ores_iam_deprovision_tenant_fn to programmatically create new tenants (copying base data from the system tenant) and soft-delete existing tenants and their associated data, respectively.
- Database Schema and Script Refinements: Removed obsolete metadata and production schema references from create_database_direct.sql, updated grants to the public schema, and adjusted unique constraints and triggers for ores_variability_feature_flags_tbl to properly incorporate tenant_id.
COMPLETED Check for uses of raw libpq code
Claude has the habit of sneaking in uses of raw libpq. We need to do a review of the code to make sure we are using sqlgen.
Notes:
- check for raw libpq in bitemporal operations.
All code has been moved into ores.database. Tickets have been raised in sqlgen.
COMPLETED Add NOTICE logging support to sqlgen code
- raised PR, waiting for review: #120: Add PostgreSQL notice processor support
Links:
BLOCKED Add bound parameters to sqlgen code
At present we are using libpq for assorted queries to avoid issues with SQL injection. We should extend sqlgen to support this.
Links:
COMPLETED Update codegen for tenancy code
We need to update code generation to take into account the new tenancy infrastructure.
This pull request significantly enhances the multi-tenancy architecture by standardizing how enum and lookup tables handle tenant identification. By ensuring all shared reference data is associated with a system tenant and implementing robust validation mechanisms, the changes promote a more consistent, auditable, and scalable data model. The introduction of updated code generation templates and new testing utilities streamlines the development and maintenance of tenant-aware database schemas.
Highlights:
- Tenancy Consolidation Plan: A detailed plan has been added outlining the strategy to consolidate all enum/lookup tables to use a system tenant (tenant 0) for consistency, eliminating tenant-less tables and ensuring all shared data is auditable and flexible for future tenant-specific needs.
- Code Generation Template Updates: The sql_schema_domain_entity_create.mustache and sql_schema_table_create.mustache templates have been updated to conditionally include a tenant_id column, adjust primary key and exclusion constraints to incorporate tenant_id, and generate tenant validation logic within insert functions.
- New Tenant-Aware Entity Models: New JSON models have been introduced for artefact_type, tenant_status, tenant_type, currency, and rounding_type entities, explicitly defining them as tenant-aware with has_tenant_id: true and system_tenant_validation: true where appropriate.
- SQL Schema and Population Script Modifications: Numerous SQL schema creation scripts across dq, iam, and refdata components have been modified to implement bi-temporal and tenant-aware properties for their respective tables. Corresponding data population scripts have been updated to insert data with the system tenant ID.
- Introduction of pgTAP Testing Framework: A new section in the SKILL.org documentation details the use of pgTAP for database unit testing, covering test file organization, structure, common patterns for validation functions and trigger defaults, and execution instructions. Dedicated pgTAP test files have been added for artefact_type, tenant_status, tenant_type, currencies, and general refdata validations.
- New Utility Scripts: New shell scripts generate_refdata_schema.sh and recreate_entity.sh have been added to automate schema generation for refdata entities and to facilitate dropping and recreating individual database entities, respectively.
COMPLETED Add entity types for tenants code
We need to be able to load and save tenants from c++.
This pull request introduces comprehensive multi-tenancy support across the system's database, code generation, and client-side interfaces. It establishes a robust framework for isolating data and operations per tenant, enhancing scalability and data governance. The changes include new tenant-specific entities, updated code generation logic to enforce tenant awareness, and extended client commands for tenant management, all while ensuring proper versioning and backward compatibility where applicable.
Highlights:
- Multi-Tenancy Architecture Enhancement: Standardized enum and lookup tables to consistently use a system tenant (tenant 0), ensuring all shared reference data is auditable and flexible for future tenant-specific needs. This eliminates tenant-less tables and promotes a more consistent data model.
- Code Generation Template Updates: Modified sql_schema_domain_entity_create.mustache and sql_schema_table_create.mustache templates to conditionally include a tenant_id column, adjust primary key and exclusion constraints to incorporate tenant_id, and generate tenant validation logic within insert functions. This also includes handling different primary key types (UUID or text) for C++ serialization/deserialization.
- New Tenant-Aware Entity Models: Introduced new JSON models for artefact_type, tenant_status, tenant_type, currency, and rounding_type entities, explicitly defining them as tenant-aware with has_tenant_id: true and system_tenant_validation: true where appropriate.
- SQL Schema and Population Script Modifications: Numerous SQL schema creation scripts across dq, iam, and refdata components have been modified to implement bi-temporal and tenant-aware properties for their respective tables. Corresponding data population scripts have been updated to insert data with the system tenant ID.
- pgTAP Testing Framework Integration: A new section in the SKILL.org documentation details the use of pgTAP for database unit testing, covering test file organization, structure, common patterns for validation functions and trigger defaults, and execution instructions. Dedicated pgTAP test files have been added for artefact_type, tenant_status, tenant_type, currencies, and general refdata validations.
- New Utility Scripts: Added new shell scripts generate_refdata_schema.sh and recreate_entity.sh to automate schema generation for refdata entities and to facilitate dropping and recreating individual database entities, respectively.
- Protocol Version Bump: The PROTOCOL_VERSION_MAJOR has been incremented to 26 and PROTOCOL_VERSION_MINOR to 1 to reflect the significant multi-tenancy support and backward-compatible changes introduced.
- Shell Command Enhancements: New commands (change-reason-categories, change-reasons, countries, tenants) have been added to the shell, and existing commands like bootstrap and login have been updated to support tenant management and display tenant-specific information.
- Tenant Context and Principal Parsing: Implemented tenant_context lookups by hostname and name, and enhanced user principal parsing (username@hostname) to correctly determine the target tenant for login and bootstrap operations, improving multi-tenant authentication flow.
COMPLETED Add sink to log to database directly code
Now that tests will use tenants and we can get a picture of tests evolving over time, it would be nice to be able to keep the logs for the tests as well. The complicated way of doing this would be to add telemetry support to unit tests. The simple way of doing this is to have a python script that just parses all the log files in one go and upload them to the telemetry tables for the tenants. With this we could also do reporting such as compare runs. Or maybe even better: create a new sink which connects to database and uploads logs.
This feature useful for unit testing and for CLI tool as well.
- Add database component
This pull request refactors the telemetry system by introducing a dedicated ores.telemetry.database library. This change aims to resolve existing circular dependencies between the core telemetry and database components, thereby enhancing the modularity and testability of the system. A key outcome is the ability to directly log telemetry data to the database, which is particularly beneficial for unit testing and validation workflows.
Highlights:
- New Library Creation: A new library, ores.telemetry.database, has been introduced to encapsulate database-specific functionality related to telemetry, effectively separating concerns from the core ores.telemetry library.
- Repository File Relocation: All telemetry repository-related files (entity, mapper, and repository implementations) have been moved from ores.telemetry to the newly created ores.telemetry.database library. This includes corresponding header and source files.
- Circular Dependency Resolution: The architectural split eliminates circular dependencies between the ores.telemetry and ores.database components, improving modularity and maintainability.
- Database Logging Sink: A new Boost.Log sink backend (database_sink_backend) has been implemented within ores.telemetry to allow direct logging of telemetry data to the database. This is particularly useful for unit testing scenarios where logs need to be captured and validated against a database.
- Messaging Component Updates: Messaging components within ores.comms.service have been updated to correctly reference the new ores.telemetry.database.lib and adjust namespace usage for database contexts.
- Build System and Examples: CMake build configurations have been updated to include the new library and manage its dependencies. New example files demonstrate how to integrate and use the database logging sink.
- Add database logging for tests
This pull request significantly enhances the testing and telemetry infrastructure by enabling direct logging of unit test telemetry data to the database. It addresses critical tenant provisioning issues, ensuring tests operate within their correct tenant contexts, and introduces a more granular tenant lifecycle management system. Furthermore, the telemetry architecture has been refactored to improve modularity and prevent recursive logging, making the system more robust and maintainable.
Highlights:
- Telemetry Database Logging Integration: Integrated a database logging sink with the unit test framework, allowing test logs to be persisted to the database for debugging and analysis. This is controlled by the new ORES_TEST_LOG_DATABASE CMake option.
- Tenant Provisioning Fix: Corrected an issue in tenant provisioning where the wrong column was selected for the tenant ID, leading to tests incorrectly using the system tenant. The tenant_id is now reliably stored in the database context.
- Three-Tier Tenant Lifecycle: Introduced a new three-tier tenant lifecycle: 'terminate' (marks inactive, preserves all data), 'deprovision' (soft-deletes temporal data, preserves non-temporal), and 'purge' (hard-deletes everything). A new SQL function ores_iam_terminate_tenant_fn was added for the 'terminate' stage.
- Recursive Logging Prevention: Implemented a skip_telemetry_guard (RAII attribute) to prevent recursive logging loops within telemetry components when telemetry operations themselves generate logs.
- Telemetry System Refactoring: Refactored the telemetry system by introducing a dedicated ores.telemetry.database library. This resolves circular dependencies between core telemetry and database components, enhancing modularity and testability.
- Unit Test Coverage: Added comprehensive unit tests for the database_sink_backend and telemetry_repository components to ensure the reliability of the new database logging and data persistence mechanisms.
COMPLETED Add system accounts for services code
Services should also "login" and start sessions. This is needed so we can associate their log files with the session. Use the same account as we use for database.
Notes:
- unit tests should also "log in" and create sessions so we can see stats.
- add performed by as per audit requirements.
This pull request significantly enhances the system's auditing capabilities by distinguishing between the database user and the application account responsible for changes. It also introduces a robust framework for managing service accounts, enabling secure authentication for automated processes. Furthermore, it addresses a critical deadlock in the telemetry system and refines several core database bootstrap and tenant management processes for improved stability and reliability.
Highlights:
- Performed By Audit Field: A new 'performed_by' field has been introduced across all 42 domain tables to track the application account initiating an action, complementing the existing 'modified_by' (database user). This change is propagated through codegen templates for C++ domain classes, mappers, protocol serialization, and Qt UI, ensuring comprehensive auditing.
- Service Account Management: New 'account_type' classifications (user, service, algorithm, LLM) are now supported, with dedicated service accounts created for non-human entities. Service accounts are designed to authenticate via sessions only, without passwords, and are integrated into the IAM schema and population scripts.
- Telemetry Deadlock Resolution: A critical fix has been implemented for a telemetry async sink deadlock by introducing a 'skip_telemetry_guard' and applying a filter to prevent recursive logging during database operations, enhancing system stability.
- SQL Bootstrap and Tenant Fixes: Various issues in SQL bootstrap and population scripts have been resolved, including proper versioning for tenant termination and ensuring system tenant context is set on service startup. A fail-fast validation was also added to 'tenant_aware_pool' acquisition to prevent operations without a defined tenant context.
COMPLETED Test shell functionality with tenancy enabled code
Ensure tenancy is working correctly with several scenarios:
- log in as super admin.
- create tenant admin account and login to tenant.
- create tenant user account and login.
Notes:
- bootstrap, stop service then start service. System is in bootstrap mode again.
- Improve Authentication
This pull request significantly enhances the client-side authentication experience by introducing dedicated helper functions for login and logout, centralizing complex logic and simplifying client implementations. It also undertakes a crucial refactoring of core messaging enums into more granular, auto-generated headers, which improves code organization and maintainability across the communication layer. The changes aim to provide a cleaner, more robust API for client interactions with the IAM service.
Highlights:
- Client-Side Authentication Helpers: Introduced a new ores.iam::client namespace with high-level login() and logout() helper functions. These helpers encapsulate the full authentication flow, significantly reducing boilerplate code in client applications like the shell and Qt clients.
- Messaging Enum Refactoring: The monolithic ores.comms/messaging/message_types.hpp header has been refactored into three distinct headers: message_type.hpp (for message type enum), compression_type.hpp (for compression type enum), and protocol.hpp (for protocol constants like magic and version). This improves modularity and reduces include dependencies.
- C++ Enum Code Generation: Added a new code generation profile and template (cpp_enum.hpp.mustache) to ores.codegen. This enables automatic generation of C++ enum classes with string conversion and stream output operators from JSON model definitions, as demonstrated by the new compression_type_enum.json and message_type_enum.json.
- Client Code Simplification: The shell client's auto_login, process_login, and process_logout functions have been refactored to utilize the new client-side authentication helpers, reducing their code footprint and improving maintainability.
- Dependency Update: The ores.iam project now explicitly links against ores.comms.lib to support the new client-side authentication helpers.
COMPLETED Fix apt-get failures on nightly build code
This pull request significantly improves the robustness of Debian package installations within the CI environment by introducing comprehensive retry mechanisms and making the installation process more configurable. It streamlines the install_debian_packages.sh script, enhances its reliability against transient network issues, and adds a convenient option for installing Valgrind, which is beneficial for memory debugging in nightly builds.
Highlights:
- Retry Logic: Implemented exponential backoff for apt-get operations in install_debian_packages.sh to enhance CI reliability, with 5 retries starting at a 5-second delay.
- APT Retries: Configured apt-get commands to use Acquire::Retries=3, providing download-level resilience for package fetching.
- Valgrind Option: Added a –with-valgrind flag to the installation script, allowing optional installation of Valgrind for specific build types like nightly builds.
- Script Refactoring and Bug Fix: Cleaned up the install_debian_packages.sh script, including converting packages to an array and fixing a bug where apt-get clean and apt-get autoremove were incorrectly placed on the same line.
- Nightly Workflow Update: The nightly build workflow was updated to utilize the new –with-valgrind flag, streamlining the Valgrind installation process.
COMPLETED Refactor tenant lookup functions to accept const context code
The tenant lookup functions (resolve_tenant_id, lookup_by_code,
lookup_by_hostname) currently take context& (non-const reference) even
though they only perform read operations. This forces callers to create
unnecessary mutable copies when they have a const context.
Current workaround in tenant_context.cpp:
// Creates unnecessary copy just to satisfy non-const parameter auto lookup_ctx = ctx.with_tenant(ctx.tenant_id()); const auto resolved = resolve_tenant_id(lookup_ctx, tenant);
Refactoring these to accept const context& would:
- Eliminate unnecessary context copies
- Better express the read-only nature of lookups
- Allow callers to use const contexts directly
COMPLETED Refactor message handlers for per-request tenant context code
Message handlers currently use a fixed database context that is set at construction time (typically with system tenant). When users from different tenants authenticate and make requests, their operations execute in the wrong tenant context, causing data isolation failures.
The session correctly stores the tenant_id from login, but handlers don't use it to create per-request database contexts. This is a security issue that can lead to cross-tenant data leakage.
See design document: doc/design/multi_tenant_message_handling.org
This pull request significantly enhances the multi-tenancy architecture by introducing a type-safe tenant_id wrapper and refactoring message handlers to use per-request database contexts. This ensures robust tenant isolation and prevents data leakage by explicitly associating each request with its correct tenant. The system tenant identifier has also been updated to a more semantically appropriate value to avoid conflicts with uninitialized UUIDs.
Highlights:
- Per-Request Tenant Context: Message handlers now create database contexts per-request using the session's tenant_id, ensuring each request executes in the correct tenant's RLS context. This fixes potential cross-tenant data leakage. A new base class, tenant_aware_handler, has been introduced to encapsulate this logic.
- Type-Safe tenant_id Wrapper: A new strong type, utility::uuid::tenant_id, has been introduced to wrap boost::uuids::uuid. It includes factory methods (system(), from_uuid(), from_string()) that prevent construction with nil UUIDs, query methods (is_system(), is_nil()) for tenant identification, and conversion methods (to_uuid(), to_string()) for interoperability. This enhances type safety and prevents accidental nil UUID usage.
- System Tenant Change: The system tenant identifier has been changed from the nil UUID (00000000-…) to the max UUID (ffffffff-…) as defined by RFC 9562. This change prevents accidental confusion with uninitialized boost::uuids::uuid values, which default-construct to nil.
- Serialization Helpers: Serialization helpers have been added for the new tenant_id type in both the binary protocol and JSON (using reflect-cpp), ensuring seamless data transfer and persistence.
- Refactored Message Handlers and Repositories: Numerous message handlers and repository methods across ores.assets, ores.dq, ores.iam, ores.refdata, ores.telemetry, and ores.variability have been updated to leverage the new tenant_aware_handler base class and accept context objects directly, promoting per-request context creation and improving tenant isolation.
- Acceptance Criteria
- Handlers create per-request database contexts using session's tenant_id
- Each request executes in the correct tenant's RLS context
- Multi-tenant concurrent requests don't interfere with each other
- ThreadSanitizer build passes under concurrent load
- Tasks
[ ]Refactoraccounts_message_handlerto use per-request context[ ]Refactorrisk_message_handlerto use per-request context[ ]Refactordq_message_handlerto use per-request context[ ]Refactorassets_message_handlerto use per-request context[ ]Refactortelemetry_message_handlerto use per-request context[ ]Refactorvariability_message_handlerto use per-request context[ ]Add multi-tenant concurrent integration test[ ]Run ThreadSanitizer build and verify no races
- Notes
PR #410 completed the foundation work:
- Added
tenant_idtosession_dataandsession_info - Made
tenant_contextimmutable - Fixed RLS policies and raw query tenant context
- Added design document
The handler refactoring pattern is:
// Before: Fixed context at construction class handler { database::context ctx_; service svc_{ctx_}; // Caches wrong tenant }; // After: Per-request context from session class handler { sqlgen::ConnectionPool<Connection> pool_; database::context make_context(const session_info& session) { return database::context(pool_, creds_, to_string(session.tenant_id)); } };
- Added
COMPLETED Review DQ metadata tables for multi-tenancy support analysis
Several DQ metadata tables have unique version indexes without tenant_id,
which prevents different tenants from having the same metadata entries:
Affected tables:
ores_dq_catalogs_tbl(name, version)ores_dq_change_reason_categories_tbl(code, version)ores_dq_change_reasons_tbl(code, version)ores_dq_coding_scheme_authority_types_tbl(code, version)ores_dq_data_domains_tbl(name, version)ores_dq_datasets_tbl(id, version)ores_dq_methodologies_tbl(id, version)ores_dq_nature_dimensions_tbl(code, version)ores_dq_origin_dimensions_tbl(code, version)ores_dq_subject_areas_tbl(name, domain_name, version)ores_dq_treatment_dimensions_tbl(code, version)
Needs analysis to determine:
- Should DQ metadata be global (shared across tenants) or tenant-specific?
- If global, how should publishing work for DQ metadata tables?
- If tenant-specific, add
tenant_idto all version unique indexes
Note: ores_dq_coding_schemes_tbl was fixed as part of the immediate publish
bug, but the broader design question remains.
This pull request significantly enhances the application's multi-tenancy capabilities and improves the user experience in the Qt client. It introduces robust mechanisms for tenant-specific data management in the database, refines data publishing logic for images, and delivers several quality-of-life improvements to the connection browser and login dialog. Additionally, a new administrative shell command streamlines role assignment, and underlying database functions are secured for proper cross-tenant operations.
Highlights:
- Multi-tenant Data Publishing: The database schema has been updated to support multi-tenant data publishing by adding tenant_id to unique version indexes across numerous tables, including assets (images, tags), DQ metadata (catalogs, change reasons, data domains, datasets, methodologies, dimensions), and reference data (countries). This ensures data uniqueness within each tenant's context.
- Image ID Resolution Fix: Publishing functions for currency and country data now correctly resolve image_id by looking up the image key from DQ images and then finding the corresponding image in the target tenant's assets table. This addresses issues where image UUIDs might differ across datasets or tenants during publishing.
- UI Usability Improvements: Several enhancements have been made to the Qt UI, particularly in the connection browser. Connections and folders are now sorted alphabetically, the tree expansion state is preserved after modifications (save, edit, delete), inline editing fields display existing names, and dialogs close the MDI sub-window instead of the main application window.
- New Shell Command for Role Assignment: A new permissions suggest command has been added to the ORE Studio Shell. This command generates a series of accounts assign-role commands, simplifying the process of assigning all available roles to a specified user account, identified by username and either hostname or tenant ID.
- Image Cache Management: The ImageCache now includes a clear() method, which is called before reloading the cache after an image dataset is published. This ensures a full refresh of image data, preventing potential issues with stale or incorrectly mapped image UUIDs following publishing operations.
- Database Security Enhancements: The ores_iam_generate_role_commands_fn PostgreSQL function has been updated with SECURITY DEFINER. This allows the function to execute with the privileges of the user who created it, enabling necessary cross-tenant access for administrative utility functions related to role assignment.
COMPLETED vcpkg is still not caching correctly code
Investigate the issue.
- Replace the removed x-gha vcpkg binary caching backend with the files provider backed by actions/cache@v4 across all 5 CI workflow files
- The x-gha backend was silently removed from vcpkg, causing all 120 packages to be rebuilt from source on every run (~21 min wasted per build)
- First run will populate the cache (cold start); subsequent runs should see vcpkg install drop from ~21 min to seconds
Affected workflows:
- canary-linux.yml (PR trigger - will run immediately)
- continuous-linux.yml (push to main - after merge)
- continuous-windows.yml (push to main - after merge)
- continuous-macos.yml (push to main - after merge)
- nightly-linux.yml (scheduled - after merge)
COMPLETED Check that data librarian can publish across tenants code
Ensure publication still works as expected.
This pull request significantly enhances the application's multi-tenancy capabilities and improves the user experience in the Qt client. It introduces robust mechanisms for tenant-specific data management in the database, refines data publishing logic for images, and delivers several quality-of-life improvements to the connection browser and login dialog. Additionally, a new administrative shell command streamlines role assignment, and underlying database functions are secured for proper cross-tenant operations.
Highlights:
- Multi-tenant Data Publishing: The database schema has been updated to support multi-tenant data publishing by adding tenant_id to unique version indexes across numerous tables, including assets (images, tags), DQ metadata (catalogs, change reasons, data domains, datasets, methodologies, dimensions), and reference data (countries). This ensures data uniqueness within each tenant's context.
- Image ID Resolution Fix: Publishing functions for currency and country data now correctly resolve image_id by looking up the image key from DQ images and then finding the corresponding image in the target tenant's assets table. This addresses issues where image UUIDs might differ across datasets or tenants during publishing.
- UI Usability Improvements: Several enhancements have been made to the Qt UI, particularly in the connection browser. Connections and folders are now sorted alphabetically, the tree expansion state is preserved after modifications (save, edit, delete), inline editing fields display existing names, and dialogs close the MDI sub-window instead of the main application window.
- New Shell Command for Role Assignment: A new permissions suggest command has been added to the ORE Studio Shell. This command generates a series of accounts assign-role commands, simplifying the process of assigning all available roles to a specified user account, identified by username and either hostname or tenant ID.
- Image Cache Management: The ImageCache now includes a clear() method, which is called before reloading the cache after an image dataset is published. This ensures a full refresh of image data, preventing potential issues with stale or incorrectly mapped image UUIDs following publishing operations.
- Database Security Enhancements: The ores_iam_generate_role_commands_fn PostgreSQL function has been updated with SECURITY DEFINER. This allows the function to execute with the privileges of the user who created it, enabling necessary cross-tenant access for administrative utility functions related to role assignment.
Errors:
=Publication Results=[FAILED] slovaris.country_flags Target: assets_images_tbl Error: Query execution failed: ERROR: duplicate key value violates unique constraint "ores_assets_images_version_uniq_idx" DETAIL: Key (image_id, version)=(14e65ed1-2e75-4f27-8e05-ba13a65a279f, 1) already exists. CONTEXT: SQL statement "insert into ores_assets_images_tbl ( tenant_id, image_id, version, key, description, svg_data, modified_by, performed_by, change_reason_code, change_commentary ) values ( p_target_tenant_id, coalesce(v_existing_image_id, r.image_id), 0, r.key, r.description, r.svg_data, current_user, current_user, 'system.external_data_import', 'Imported from DQ dataset: ' || v_dataset_name ) returning version" PL/pgSQL function ores_dq_images_publish_fn(uuid,uuid,text) line 63 at SQL statement
[SUCCESS] slovaris.currencies Target: refdata_currencies_tbl Records: 100 inserted, 0 updated, 0 skipped, 0 deleted
[FAILED] slovaris.countries Target: refdata_countries_tbl Error: Query execution failed: ERROR: duplicate key value violates unique constraint "ores_refdata_countries_version_uniq_idx" DETAIL: Key (alpha2_code, version)=(AL, 1) already exists. CONTEXT: SQL statement "insert into ores_refdata_countries_tbl ( tenant_id, alpha2_code, version, alpha3_code, numeric_code, name, official_name, coding_scheme_code, image_id, modified_by, performed_by, change_reason_code, change_commentary ) values ( p_target_tenant_id, r.alpha2_code, 0, r.alpha3_code, r.numeric_code, r.name, r.official_name, v_coding_scheme_code, v_resolved_image_id, current_user, current_user, 'system.external_data_import', 'Imported from DQ dataset: ' || v_dataset_name ) returning version" PL/pgSQL function ores_dq_countries_publish_fn(uuid,uuid,text) line 82 at SQL statement
[SUCCESS] geo.ip2country Target: geo_ip2country_tbl Records: 512186 inserted, 0 updated, 0 skipped, 0 deleted
=Summary=Datasets processed: 4 Succeeded: 2, Failed: 2 Total records: 512286 inserted, 0 updated, 0 skipped, 0 deleted
COMPLETED Check that eventing works correctly across tenants code
Create events from different tenants and ensure they are processed correctly.
This pull request significantly enhances the multi-tenancy isolation within the notification system. By integrating tenant_id across the entire notification flow—from database triggers generating events, through the event bus, and finally to the subscription manager—it ensures that sensitive entity change notifications are strictly confined to their respective tenant boundaries. This change is crucial for maintaining data segregation and security in a multi-tenant environment, while also preserving backward compatibility for existing broadcast mechanisms.
Highlights:
- Tenant ID Propagation: The tenant_id is now consistently passed through the entire notification pipeline, from SQL triggers to domain events and the subscription manager.
- SQL Trigger Enhancement: SQL triggers have been updated to embed the tenant_id within their JSONB notification payloads, enabling tenant-specific event sourcing.
- Subscription Manager Filtering: The subscription_manager::notify() method now incorporates tenant-aware filtering, ensuring that notifications are only delivered to sessions associated with the relevant tenant.
- Backward Compatibility: The system gracefully handles cases where tenant_id is empty or the session service is not configured, falling back to broadcasting notifications to all subscribers.
- Comprehensive Testing: Five new test cases have been added to validate tenant matching, broadcast behavior, cross-tenant isolation, pre-login session handling, and scenarios without a configured session service.
Footer
| Previous: Version Zero |