Sprint Backlog 13
Sprint Mission
- Add trade and scheduling support.
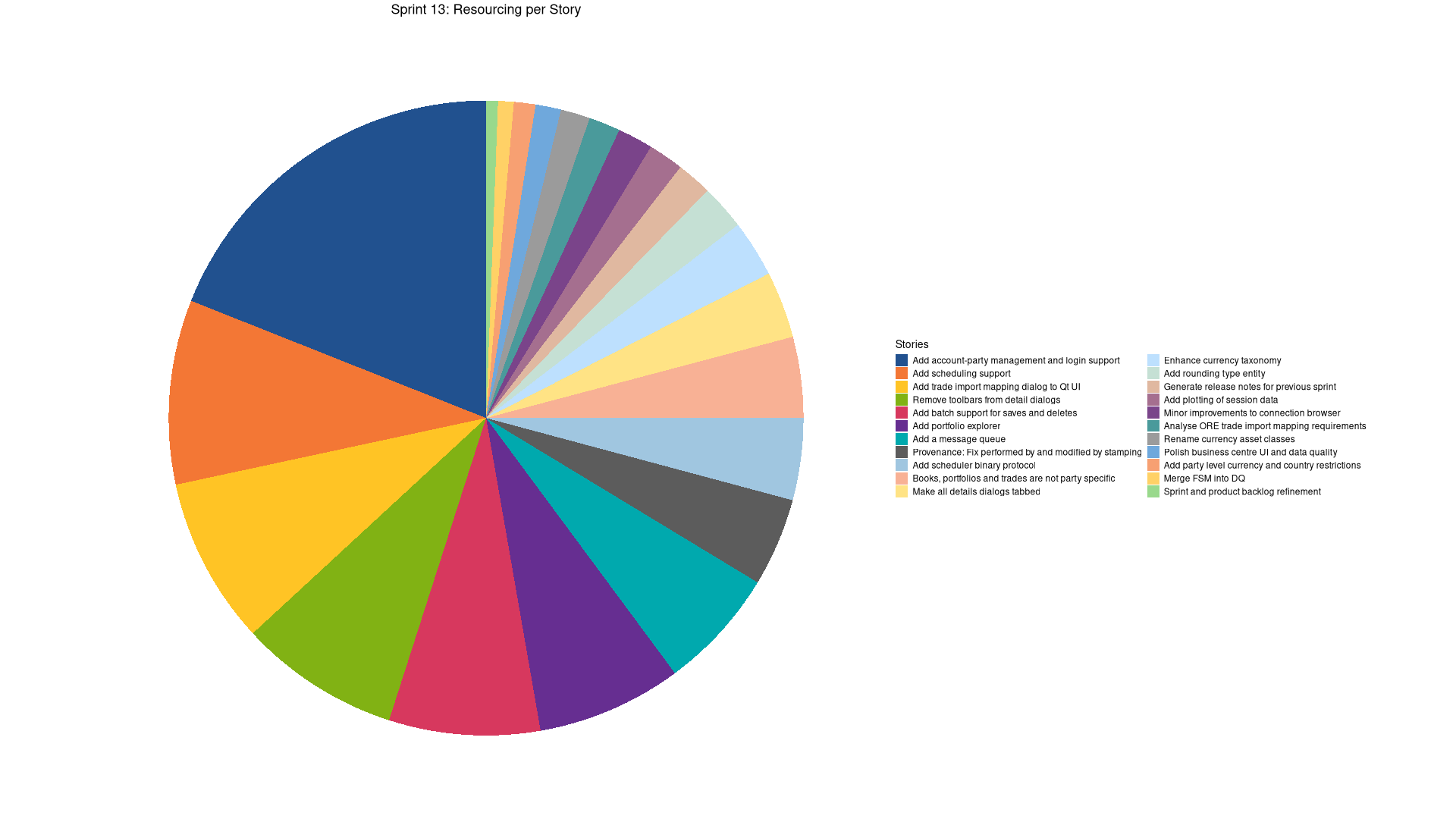
Stories
Active
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 4:04 | 100.0 | |||
| Stories | 4:04 | 100.0 | |||
| Active | 4:04 | 100.0 | |||
| code | Add batch support for saves and deletes | 4:04 | 100.0 |
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 72:13 | 100.0 | |||
| Stories | 72:13 | 100.0 | |||
| Active | 72:13 | 100.0 | |||
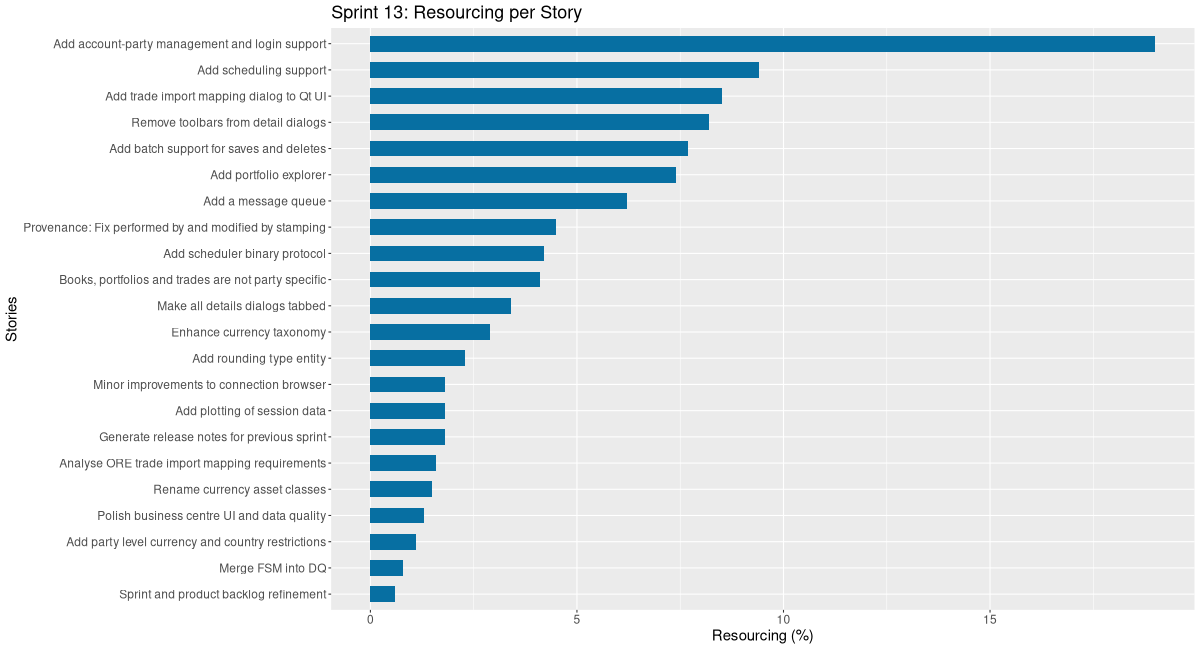
| agile | Sprint and product backlog refinement | 0:26 | 0.6 | ||
| infra | Generate release notes for previous sprint | 1:16 | 1.8 | ||
| code | Merge FSM into DQ | 0:34 | 0.8 | ||
| code | Make all details dialogs tabbed | 2:26 | 3.4 | ||
| code | Provenance: Fix performed by and modified by stamping | 3:17 | 4.5 | ||
| code | Add plotting of session data | 1:19 | 1.8 | ||
| code | Add account-party management and login support | 13:43 | 19.0 | ||
| code | Add rounding type entity | 1:40 | 2.3 | ||
| code | Polish business centre UI and data quality | 0:58 | 1.3 | ||
| code | Enhance currency taxonomy | 2:06 | 2.9 | ||
| code | Books, portfolios and trades are not party specific | 2:59 | 4.1 | ||
| code | Minor improvements to connection browser | 1:17 | 1.8 | ||
| code | Rename currency asset classes | 1:05 | 1.5 | ||
| code | Remove toolbars from detail dialogs | 5:57 | 8.2 | ||
| code | Add portfolio explorer | 5:19 | 7.4 | ||
| code | Analyse ORE trade import mapping requirements | 1:08 | 1.6 | ||
| code | Add scheduler binary protocol | 3:00 | 4.2 | ||
| code | Add scheduling support | 6:48 | 9.4 | ||
| code | Add a message queue | 4:30 | 6.2 | ||
| code | Add batch support for saves and deletes | 5:32 | 7.7 | ||
| code | Add party level currency and country restrictions | 0:46 | 1.1 | ||
| code | Add trade import mapping dialog to Qt UI | 6:07 | 8.5 |
COMPLETED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
COMPLETED Generate release notes for previous sprint infra
We now have so much text that we are bursting the prompt window. We need to first feed the sprint backlog to summarise it and then use the summarised output to generate the release notes. The process is a bit more time consuming now.
COMPLETED Merge FSM into DQ code
We considered first adding FSM as a stand alone component, but in reality it is part of the DQ framework. DQ is becoming a meta-data framework for all aspects related to ensuring the data quality in the system. We will probably also put four eyes into DQ.
This pull request refactors the Finite State Machine (FSM) component by integrating it directly into the Data Quality (DQ) layer. This consolidation is driven by the understanding that state machines serve as critical metadata infrastructure for managing data quality. The changes involve a comprehensive renaming of SQL objects and file paths to align FSM with its new home within DQ, ensuring a more logical and maintainable architecture.
Highlights:
- FSM Component Consolidation: The Finite State Machine (FSM) component has been fully integrated into the Data Quality (DQ) layer, recognizing state machines as core metadata infrastructure for data quality.
- SQL Identifier Renaming: All SQL identifiers previously prefixed with ores_fsm_* have been systematically renamed to ores_dq_fsm_* to reflect their new organizational structure within the DQ component.
- File Relocation: All FSM-related SQL schema, trigger, RLS policy, and population scripts have been moved from their original fsm/ subdirectories into the dq/ subdirectories.
- Notification Channel Updates: PostgreSQL pg_notify channels for FSM entities (machines, states, transitions) have been updated to use the new ores_dq_fsm_ prefix.
- Entity String Renaming: Internal entity strings used for FSM components have been updated from ores.fsm.* to ores.dq.fsm.*.
COMPLETED Make all details dialogs tabbed code
At present we have very long dialogs for details. Make all of them tabbed.
This pull request introduces significant UI enhancements and refactoring across various detail dialogs and user-specific windows. The primary goal is to standardize the layout of detail dialogs by adopting a tabbed interface, centralizing provenance information into a dedicated 'Provenance' tab, and improving the overall user experience through better organization and visual cues. It also modernizes user account and session management by converting them to MDI subwindows, aligning with a more integrated application feel.
Highlights:
- Country Detail Dialog: Moved the flag display from a separate tab into the General tab as a group box, resulting in a dialog with two tabs: General and Provenance.
- Currency Detail Dialog: Relocated the icon button from a floating position between the toolbar and tabs into the General tab within an Icon group box.
- Main Window Menus: Added a top-level '&Trading' menu between Data and System, moving the 'Trades' action into it and adding 'Trades' to the toolbar.
- Data Governance Submenu: Introduced a '&Dimensions' submenu within 'Data Governance', containing 'Origin', 'Nature', and 'Treatment Dimension' actions.
- Change Commentary Field Removal: Removed the editable 'Change Commentary' field from the General tab in eight specific detail dialogs (Methodology, TreatmentDimension, DataDomain, CodingSchemeAuthorityType, CodingScheme, SubjectArea, Catalog, Dataset), while retaining a read-only version in the Provenance tab.
- Methodology Detail Dialog: Enlarged the 'Implementation' text area by increasing its minimum height from 100 to 300.
- My Sessions Window: Converted 'My Sessions' from a floating QDialog to an MDI subwindow, allowing re-triggering to bring it to the front.
- My Account Window: Converted 'My Account' from a modal QDialog to a QWidget MDI subwindow, featuring a toolbar with a 'Save Email' action and three tabs: General (account info), Security (change password), and Sessions (session count + 'View History' button). The 'View History' button now emits a signal to open 'My Sessions' in the main window.
- Entity Detail Dialog: Implemented a 32x24 country flag label next to the 'Business Centre' combo box, which updates dynamically upon selection changes via the image cache.
COMPLETED Provenance: Fix performed by and modified by stamping code
This pull request enhances the system's provenance tracking and account validation mechanisms. It ensures that actions performed within the database, particularly during tenant provisioning and asset assignments, accurately record the initiating user rather than generic system accounts. By refining account validation logic and optimizing the database initialization sequence, the changes improve data integrity and auditability.
Highlights:
- Account Validation: Removed an escape hatch from ores_iam_validate_account_username_fn that previously allowed any DB session user to bypass accounts-table validation by matching current_user.
- Database Population Order: Reordered foundation_populate.sql to ensure IAM service accounts are populated before Data Quality Framework and Reference Data sections, allowing validate_account_username_fn to find service accounts when triggers fire.
- Provenance Tracking: Introduced ores_iam_current_actor_fn() to read the app.current_actor GUC and used this resolved actor (falling back to current_user) in all inserts within ores_iam_provision_tenant_fn to correctly record modified_by/performed_by.
- Assigned By Validation: Replaced silent current_user defaults for assigned_by in ores_assets_image_tags_insert_fn and ores_iam_account_roles_insert_fn with calls to ores_iam_validate_account_username_fn() for proper bootstrap-aware validation.
COMPLETED Add plotting of session data code
This pull request significantly enhances the client's ability to monitor and visualize network session data, while improving the server's data collection and persistence mechanisms. It introduces real-time RTT sampling, ensures accurate byte counter reporting, and provides a new API and UI components for displaying historical session performance metrics. The changes also include robust database schema and documentation for handling time-series data efficiently.
Highlights:
- Session Byte Counters Fixed: The bytes_sent and bytes_received counters are now synchronized from the live connection before logout, resolving an issue where 'My Sessions' displayed '0 B'.
- RTT Sampling and Persistence: Client pings now carry the previous heartbeat RTT (latency_ms). The server records session_sample data (bytes + latency) at each heartbeat tick and persists these batches to the ores_iam_session_samples_tbl TimescaleDB hypertable upon logout.
- New Protocol for Session Samples: A new protocol pair, get_session_samples_request (0x2072) and get_session_samples_response (0x2073), has been introduced to allow clients to fetch ordered time-series session samples, with server-side authorization checks.
- Enhanced Connection Tooltip: The status-bar plug icon now provides a dynamic tooltip displaying live server address, bytes sent/received, and RTT when connected, or a 'Disconnected for N s' message during reconnection attempts.
- Interactive Session Chart: Selecting a session in 'My Sessions' now fetches and plots bytes_sent and bytes_received over time using a new QChartView/QLineSeries panel, requiring the qt6-charts vcpkg dependency.
- TimescaleDB Documentation: The SQL skill documentation has been updated with a dedicated section on TimescaleDB time-series tables, covering hypertables, chunk intervals, compression, retention, and a canonical example.
COMPLETED Add account-party management and login support code
This pull request introduces comprehensive multi-party support across the system, enabling greater flexibility in how user accounts are associated with organizational entities. It refines the authentication process to incorporate party selection, provides administrative tools for managing these associations, and updates the underlying communication protocols and database schema to support the new functionality. The changes aim to enhance user management and data isolation capabilities.
Highlights:
- Multi-Party Login Flow: Implemented a multi-party login mechanism where user accounts can be linked to multiple organizational parties. The server now returns a list of available parties, allowing the client to present a picker for selection, or auto-selecting if only one party is assigned. This includes new wire protocol messages (select_party_request, select_party_response) and extensions to the login_response to carry party information.
- Account-Party Management UI and API: Added a new 'Parties' tab to the AccountDetailDialog in the Qt client, featuring an AccountPartiesWidget. This widget allows administrators to add or remove party assignments for an account via new server-side API handlers (get_account_parties_by_account, save_account_party, delete_account_party).
- Protocol Version Bump: The messaging protocol major version was incremented from 37 to 38 due to breaking changes in the login_response wire format, accommodating the new party selection fields.
- System Party Auto-Assignment: Modified the bootstrap process to automatically assign the system party to the initial admin account, ensuring successful login for newly provisioned tenants. A new PostgreSQL function, ores_iam_account_parties_system_party_id_fn(), was introduced to look up the system party ID.
- Documentation Updates: New documentation (multi_party.org) was added detailing the multi-party login flow, account-party rules, and wire protocol changes. Existing documentation was updated to reference this new content.
COMPLETED Add rounding type entity code
This pull request introduces a new rounding_type entity, integrating it fully across the application's data, service, and user interface layers. The primary goal is to provide a robust and user-friendly mechanism for defining and managing various financial rounding methods, which can then be referenced by other entities like currencies. This enhancement improves data consistency and user experience by offering a structured way to handle rounding configurations, along with a more organized main menu for data management.
Highlights:
- New Entity: Rounding Type: Introduced a new rounding_type domain entity, complete with its JSON model definition, repository, messaging protocol, and service layer declarations for full CRUD (Create, Read, Update, Delete) and history operations.
- Full Qt Stack for Rounding Types: Implemented a comprehensive Qt user interface for managing rounding types, including a ClientRoundingTypeModel for data display, RoundingTypeMdiWindow for listing, RoundingTypeDetailDialog for viewing/editing, and RoundingTypeHistoryDialog for version tracking.
- Currency Detail Dialog Enhancement: Replaced the free-text roundingTypeEdit field in CurrencyDetailDialog with a roundingTypeCombo QComboBox. This combo box is populated asynchronously from the server, sorted by display order, and provides tooltips from the description field.
- Navigation Restructure: Restructured the main application's 'Data' menu. Core entities like Currencies and Countries are now top-level, while auxiliary types, including the new Rounding Types, are consolidated under a new 'Auxiliary Data' submenu for better organization.
- Integration with Currency Workflow: Added 'Rounding Types' toolbar buttons to both the CurrencyDetailDialog and CurrencyMdiWindow, providing quick access to the rounding types management interface and wiring the CurrencyController to relay requests to the new RoundingTypeController.
- SQL Data Enrichment: Enriched the descriptions of existing rounding types in the SQL population script with 2-decimal place numeric examples for 'Up', 'Down', 'Closest', 'Floor', and 'Ceiling' methods.
COMPLETED Polish business centre UI and data quality code
Several data quality and UI issues with business centres.
- WRLD should have UN flag and source = Internal.
- Hard-code NY* centres (NYFD, NYSE, USNY) during population to US country.
- Add a city name field parsed from descriptions (regex for parenthesised text).
- Do not display description column by default.
- Country should be a combo box.
- Fix missing country flags.
- Do not display coding scheme column by default.
- Move country column next to code.
- Reduce recorded_at column width.
This pull request focuses on enhancing the data quality and user interface for business centres. It introduces a new 'city_name' field, derived from existing descriptions, and integrates it across the database, C++ domain models, and the Qt UI. Additionally, it includes specific data fixes for certain business centre codes and refines the display of business centre information in the UI.
Highlights:
- SQL Data Enhancements: Added a 'city_name' column to the business centres reference data table and implemented logic to automatically derive city names from existing descriptions during data population.
- Data Quality Fixes: Hard-coded the country for specific business centre codes (NYFD, NYSE) to 'US' and ensured the correct US flag is displayed in the FpML artefact. The 'WRLD' system business centre was also updated with 'source=Internal' and assigned a UN flag.
- C++ Model Updates: Incorporated the new 'city_name' field into the 'business_centre' domain struct, its entity representation, mapper, and the binary messaging protocol, leading to a major protocol version bump to v38.0.
- Qt UI Improvements: Reordered columns in the business centre list view to prioritize 'Code', 'Country', and 'City', added a dedicated 'City' column, and set 'Description' and 'Coding Scheme' to be hidden by default. The 'Recorded At' column width was fixed, and the country selection combo box in the detail dialog was made non-editable, while also displaying the derived city name.
COMPLETED Enhance currency taxonomy code
This pull request significantly enhances the currency classification system by moving from a monolithic free-text field to a more structured and governed approach. The change introduces distinct categories for a currency's asset class and its market tier, allowing for better data integrity, extensibility, and auditability. This refactoring impacts all layers of the application, from the database schema and domain models to the messaging protocols and user interfaces, providing a robust foundation for future currency management.
Highlights:
- Currency Taxonomy Restructuring: Replaced the single 'currency_type' free-text field with two structured lookup fields: 'asset_class' (fiat, crypto, commodity, synthetic, supranational) and 'market_tier' (g10, emerging, exotic, frontier, historical) to provide a more granular and accurate classification of currencies.
- New Reference Data Entities: Introduced two new reference-data entities, 'currency_asset_class' and 'currency_market_tier', complete with full stack coverage including SQL tables, domain types, repositories, services, messaging (CRUD + history), Qt UI, Wt UI, and CLI support.
- Protocol Version Update: Updated the binary protocol to version 41.0, which is a breaking change due to the replacement of the 'currency_type' wire field with the new 'asset_class' and 'market_tier' fields, and the addition of new message types for the new lookup entities.
- Comprehensive Codebase Updates: Addressed and fixed all build failures across test files, wire-format comments, and application code that previously referenced the now-removed 'currency_type' field, ensuring full integration of the new taxonomy.
COMPLETED Books, portfolios and trades are not party specific code
At present I can see these entities from any party in a tenant.
This pull request introduces party isolation for key entities like books, portfolios, and trades, enhancing data security and access control. It also improves the user interface by adding party context and parent portfolio selection features, while centralizing flag icon handling for better code maintainability and consistency.
Highlights:
- Party Isolation: Enforced party isolation for books, portfolios, and trades using strict RLS policies, ensuring data visibility is limited to the appropriate party context.
- Session Management: Enhanced session data to include party context, enabling party-level RLS enforcement via update_session_party() and make_request_context().
- UI Updates: Improved UI by displaying party name in the portfolio detail dialog, pre-populating party_id in create mode, and adding parent portfolio selectors to both portfolio and book detail dialogs.
- Flag Icon Handling: Centralized flag icon setup in FlagIconHelper, replacing scattered per-dialog lambdas with a more maintainable and consistent approach.
COMPLETED Minor improvements to connection browser code
Quality of life improvements to connection browser so that we don't have to spend so much time entering data manually.
This pull request introduces a significant refactoring of how server environments and connections are managed, separating host/port configurations from credential storage. It enhances the user interface with a unified connection browser, new duplication capabilities, and an improved login experience. The underlying database schema has been updated to support these changes, including an automatic migration process for existing data.
Highlights:
- Environment and Connection Separation: Refactored the server_environment type into two distinct domain types: environment (host + port, no credentials) and connection (credentials, optionally linked to an environment). When a connection is linked to an environment, its host/port are resolved live from the environment.
- SQLite Database Migration: Introduced new SQLite tables for environments, connections, and connection_tags. Existing server_environments data is automatically migrated to the new connections table on the first launch, ensuring backward compatibility.
- Unified Connection Browser Tree: The connection browser now displays folders, environments, and connections in a single, unified tree structure with distinct icons. Drag-and-drop functionality between folders has been improved to correctly restore expansion states.
- Duplicate Action: Added a new 'Duplicate' action accessible via the toolbar and context menus. This allows users to create a copy of any selected node (folder, environment, or connection), appending ' (copy)' to its name.
- Inherited Tags and Detail Panel Enhancements: Connections linked to an environment now display the environment's tags as outlined badges in the detail panel, distinguishing them from the connection's own filled badges. The detail panel also shows resolved host/port for environment-linked connections in a grayed, italic style with a tooltip indicating the source environment.
- Login Dialog Quick-Connect Combo: The login dialog's separate environment combo and saved-connections button have been replaced with a single, unified quick-connect combo box. This combo categorizes entries with 'Manual', 'Environments', and 'Connections' headers. Selecting an environment pre-fills and locks host/port fields, while selecting a connection pre-fills all four login fields.
- New Icons: New 'Keyboard' (for manual entry) and 'Copy' (for duplication) icons have been added to the icon system, with Fluent UI and Solarized variants.
COMPLETED Add concept of "named environments" to connection manager code
Rationale: implemented as part of improvements to connection browser.
It would be nice if we could do "local2! instead of "localhost@51004". For this we need to have the notion of "named environments". This could be another entry in the connection manager. Maybe a separate tree widget.
Users could then choose an environment and it would automatically populate host and port. These would also show up in drop down box. If using an environment, title bar would show that as well as host and port.
COMPLETED Rename currency asset classes code
We should avoid the term "asset classes" unless it is used in the usual asset class context. Many of the values are not really what one things of asset classes.
COMPLETED Remove toolbars from detail dialogs code
At present we have toolbars in detail dialogs. These should just have buttons. Actions: delete, cancel, save.
COMPLETED Add portfolio explorer code
Add a combined PortfolioBookTreeMdiWindow that replaces the separate
flat-list views for portfolios and books with a unified hierarchical tree
scoped to the active session party. Clicking a node in the tree filters the
trade table on the right to show only trades within that branch.
Depends on: "Extend login flow with party selection" (party must be bound to session before the tree can scope correctly).
This pull request delivers a significant new feature: the Portfolio Explorer. This interactive MDI window provides a hierarchical view of portfolios and books, allowing users to intuitively navigate their financial structures. By integrating dynamic trade filtering, persistent UI settings, and real-time data updates, it greatly enhances the user's ability to monitor and analyze trades within specific segments of their portfolio. The changes also include necessary backend modifications to support this advanced filtering and UI state management.
Highlights:
- New Portfolio Explorer Widget: Introduced a new MDI window that displays a full portfolio/book hierarchy for the session party on the left, with a filtered trade table on the right. This allows users to navigate their portfolio structure and view associated trades.
- Dynamic Trade Filtering and Navigation: Implemented dynamic trade filtering where selecting any node in the portfolio/book tree scopes the trade table to that specific subtree. A breadcrumb bar provides clickable navigation for the current path.
- Trade Count Aggregation: Added functionality to fetch and display trade counts per-book, with these counts aggregating up through portfolio and party nodes in the tree view.
- UI Persistence and Stale Indicators: Ensured window size, splitter position, and trade table column states are persisted across sessions. A stale indicator pulses on book, portfolio, or trade change notifications, alerting users to updated data.
- Enhanced Trade Protocol and Backend Filtering: Updated the trade protocol (PROTOCOL_VERSION_MAJOR bumped to 43) to support optional book_id and portfolio_id filters in trade requests, enabling server-side filtering for the new widget. Corresponding repository and service methods were added to handle this filtering, including recursive CTEs for portfolio subtrees.
- Generic UI Component Improvement: Extended EntityListMdiWindow::initializeTableSettings() to accept an optional QSplitter* parameter, allowing splitter state to be saved and restored alongside window size and column headers for any MDI window using this base class.
- New Eventing for Books and Portfolios: Added book_changed_event and portfolio_changed_event to the eventing system, allowing the UI to react to real-time changes in these entities.
- Acceptance Criteria
- A single MDI window contains a horizontal splitter: tree on the left, trade table on the right.
- The tree renders the full portfolio hierarchy for the session party, with books as leaves under their parent portfolios.
- Node icons are visually distinct:
- Real portfolio:
briefcase_20_filled - Virtual portfolio (
is_virtual=1):briefcase_20_regular - Trading book (
is_trading_book=1):book_open_20_filled - Banking/Risk book (
is_trading_book=0):book_open_20_regular
- Real portfolio:
- Selecting any node filters the trade table to trades within that subtree.
- A breadcrumb label above the trade table shows the selected path.
- The reload button acquires a stale/pulsing indicator when a portfolio, book, or trade change notification arrives.
- Pagination widget present on the trade table (server-side).
- Wireframes
- Main layout
┌─ Portfolio Book Tree ──────────────────────────────────────────────────────────┐ │ [↻ Reload] │ [+ Portfolio] [+ Book] [✎ Edit] [🗑 Delete] [⏱ History] │ ├────────────────────────────────────────────────────────────────────────────────┤ │ Party: (bound from session — read-only) │ ├──────────────────────────────┬─────────────────────────────────────────────────┤ │ │ Trades › Rates › IR › Rates_EUR_01 │ │ ▼ ▣ Rates │ ┌───────────┬──────────┬──────┬──────┬─────────┐│ │ ▼ ▣ Rates IR │ │ Ext ID │ Type │ Cpty │ Date │ Matures ││ │ ├─ ◉ Rates_EUR_01 ● │ ├───────────┼──────────┼──────┼──────┼─────────┤│ │ └─ ◉ Rates_USD_01 │ │ UTI-0001 │ IRS │ DBAG │01-25 │ 01-30 ││ │ ▼ ▣ Rates FX │ │ UTI-0002 │ FxFwd │ HSBC │03-25 │ 09-25 ││ │ └─ ○ FX_EUR_Vol_01 │ │ UTI-0003 │ CapFloor │ DBAG │11-24 │ 11-27 ││ │ │ └───────────┴──────────┴──────┴──────┴─────────┘│ │ ▼ □ Regulatory [virtual] │ [←] Page 1 of 3 [→] Load All (12) │ │ ▼ □ Rates Reg [virtual] │ │ │ ├─ ◉ Rates_EUR_01 │ │ │ └─ ◉ Rates_USD_01 │ │ │ │ │ │ ▼ ▣ Equities │ │ │ └─ ○ Equities_EU_01 │ │ ├──────────────────────────────┴─────────────────────────────────────────────────┤ │ 12 trades • Rates_EUR_01 (Trading Book) │ └────────────────────────────────────────────────────────────────────────────────┘
- Icon legend
▣ briefcase_20_filled Real portfolio (non-virtual) □ briefcase_20_regular Virtual portfolio (is_virtual = 1) ◉ book_open_20_filled Trading book (is_trading_book = 1) ○ book_open_20_regular Banking/Risk book (is_trading_book = 0) ● stale indicator on selected node (pending reload)
- Breadcrumb scope behaviour
Click: ▣ Rates → Trades › Rates (all trades in branch) Click: ▣ Rates IR → Trades › Rates › IR (subtree trades) Click: ◉ Rates_EUR_01 → Trades › Rates › IR › Rates_EUR_01 (book trades) Click: □ Regulatory → Trades › Regulatory (same trades, virtual view)
Virtual portfolios surface the same underlying trades as their real counterparts; they are reporting overlays, not separate trade containers.
- Proposed Qt component structure
PortfolioBookTreeMdiWindow ├── QToolBar ├── QSplitter (horizontal) │ ├── QTreeView ← PortfolioBookTreeModel (QAbstractItemModel) │ │ items: PortfolioTreeNode / BookTreeNode │ └── QWidget (right panel) │ ├── Breadcrumb QLabel │ ├── QTableView ← ClientFilteredTradeModel │ └── PaginationWidget └── Status QLabel
- Main layout
COMPLETED Analyse ORE trade import mapping requirements code
ORE portfolio XML files contain trades with string-based references for
counterparties (CounterParty), netting sets (NettingSetId), and portfolio
labels (PortfolioIds). ORES uses UUID foreign keys for books, counterparties,
and portfolios. ORE has no concept of books at all.
We need to analyse the mapping requirements and design an approach for resolving these references during import. Key questions:
- How should users map ORE
CounterPartystrings to ORES counterparty UUIDs? Options: auto-create counterparties, present a mapping dialog, or use a configuration file. - How should users assign an ORES book to imported trades? ORE has no book concept, so this must be user-provided.
- Should ORE
PortfolioIdsbe mapped to ORES portfolios, or ignored? - Should we support batch import configurations that can be saved and reused?
Acceptance criteria:
- Document the mapping requirements and chosen approach.
- Create a design for the mapping dialog or configuration mechanism.
- Identify all fields that need external resolution vs. direct mapping.
COMPLETED Add scheduler binary protocol code
Add binary protocol support for the ores.scheduler subsystem, enabling clients
to manage pg_cron jobs via the existing comms layer.
Key design decisions:
- Scheduler subsystem assigned message type range
0x9000–0x9FFF(SCHEDULER_SUBSYSTEM_MIN/MAX constants added to protocol.hpp). - Protocol version bumped to
45.0(breaking change). - Four request/response pairs implemented:
get_job_definitions_request/response(0x9000/0x9001): list all jobsschedule_job_request/response(0x9002/0x9003): create and activate a jobunschedule_job_request/response(0x9004/0x9005): deactivate a jobget_job_history_request/response(0x9006/0x9007): execution history
- Handler registered in
ores.comms.service/app/application.cppvia the existing registrar pattern (same as trading subsystem). - Custom
rfl::Reflectorspecialisations forcron_expressionandjob_statusplaced inores.scheduler/include/ores.scheduler/rfl/reflectors.hppto avoid circular dependency withores.utility.
- Tasks
[X]Step 1: Add message types (0x9000–0x9007) tomessage_type.hpp[X]Step 2: Add SCHEDULER_SUBSYSTEM_MIN/MAX + version 45.0 toprotocol.hpp[X]Step 3: Createscheduler_protocol.hpp+scheduler_protocol.cpp[X]Step 4: Createscheduler_message_handler.hpp+scheduler_message_handler.cpp[X]Step 5: Createregistrar.hpp+registrar.cpp[X]Step 6: Wire intoores.comms.service(CMakeLists + application.cpp)[X]Step 7: Verify:ores.scheduler.libbuilds, 51 tests pass
- Notes
Story is BLOCKED pending PR review and testing.
Pull Request: (pending) Branch:
feature/scheduler-binary-protocol
COMPLETED Add scheduling support code
Build a library called ores.scheduler that wraps the PostgreSQL pg_cron
extension.
- Overview
- Use a Quartz.NET-style fluent API. Strictly distinguish between job_definition (the record in cron.job) and job_instance (the execution record in cron.job_run_details).
- Create a job_definition class with properties:
job_id,job_name,command, and schedule_expression. - Create a job_instance struct for telemetry:
instance_id,status, andreturn_message. - Implement a
job_definition_builderusing the fluent pattern. - Implement a
cron_schedulerclass that uses sqlgen to execute thecron.scheduleandcron.unschedulefunctions. - Include a method
get_job_history(job_id)that returns a vector ofjob_instance. - The Core Concept
The library, ores.scheduler, is a fluent C++ wrapper for PostgreSQL's pg_cron extension. It follows the Quartz.NET pattern but persists all state in the database.
job_definition: The persistent "Plan" (stored in cron.job).job_instance: The historical "Execution" (stored in cron.job_run_details).cron_scheduler: The coordinator that translates C++ calls into SQL.- The Domain Model (Key Classes)
job_definition: This class represents the identity and command of a task.
Fields:
job_id: The internal Postgres ID (assigned after scheduling).job_name: A unique user-provided string.command: The raw SQL to execute.schedule_expression: The cron string (e.g., 0 0 * * *).database_name: Which DB to run the command against.
job_instance: This is a read-only record of a specific trigger event.
instance_id: Unique run ID.parent_job_id: Link to the job_definition.status: Enum (starting, finished, failed).return_message: The stdout or error message from Postgres.start_time / end_time: Timestamps of the execution.
job_definition_builder: The fluent interface to create definitions.
with_name(string)with_command(string)with_cron_schedule(string)- The Lifecycle Story
Phase 1: Registration
The user uses the job_definition_builder to create a job_definition object. They pass this to the cron_scheduler. The scheduler executes:
SELECT cron.schedule('job_name', 'schedule_expression', 'command');
Phase 2: The Trigger (Database Side)
At the scheduled time, the pg_cron background worker wakes up. It ignores the C++ app entirely. It creates a new job_instance in the database, runs the SQL command, and updates the job_instance with the result (success or failure).
Phase 3: Observation (C++ Side)
The C++ app can "re-sync" by asking the cron_scheduler for updates.
get_all_definitions(): Returns a list of job_definition objects currently in the DB.get_recent_instances(job_id): Queries the history table to return a list of job_instance objects.
Merged stories:
Add pg_cron extension for scheduling
We should install pg_cron extension:
pg_cron is a simple cron-based job scheduler for PostgreSQL (10 or higher) that runs inside the database as an extension.
Links:
Add scheduling support
Build a library called ores.scheduler that wraps the PostgreSQL pg_cron
extension using a Quartz.NET-style fluent API. Strictly distinguishes between
job_definition (the record in cron.job) and job_instance (the execution
record in cron.job_run_details).
Key design decisions from analysis:
croncpp(already in vcpkg ports) used for a strongly-typedcron_expressionwrapper class with C++23std::expectederror handling.std::chrono::system_clock::time_pointfor all timestamps.utility::uuid::tenant_id(fromores.utility, no IAM dependency) for tenant isolation;boost::uuids::uuidfor party_id.- Own table
ores_scheduler_job_definitions_tbl(hand-crafted SQL, not codegen, becausecron_job_id bigintandis_active integerdon't fit standard domain entity templates) linked to pg_cron viacron_job_id(bigint FK tocron.job.jobid). - Job instances read directly from
cron.job_run_detailsvia raw SQL join — no mirror table needed for Phase 1. descriptionandis_activecolumns included now for the future UI PR.- Phase 2 (separate PR): binary protocol messages for schedule/list/history.
cron_expressionbridges pg_cron's 5-field Unix format and croncpp's 6-field format transparently; users always see standard cron strings.
- Tasks
[X]Step 1: SQL setup — pg_cron extension + table + RLS policies[X]Step 2: C++ library scaffold — directory, CMakeLists, umbrella header[X]Step 3: Domain types —cron_expression,job_status,job_definition,job_instance[X]Step 4: Builder —job_definition_builderfluent API[X]Step 5: Repository —job_definition_repository(reads/writes our table)[X]Step 6: Service —cron_scheduler(wraps pg_cron calls + uses repository)[X]Step 7: Generators —generate_synthetic_job_definition[X]Step 8: Tests — domain/builder unit tests (10 test cases, 51 assertions)[X]Step 9: Wire into build — CMakeLists, vcpkg.json, register in projects/
COMPLETED Add a message queue code
We need basic infrastructure for queuing.
COMPLETED Add batch support for saves and deletes code
This pull request significantly enhances the efficiency and consistency of data manipulation operations across various services by implementing atomic batch processing for both saving and deleting entities. This refactoring simplifies the API for handling multiple entities, ensuring that operations are treated as a single unit of work, and provides clearer, consolidated feedback to the client.
Highlights:
- Atomic Batch Operations: Refactored all messaging protocols to use atomic batch save/delete semantics, ensuring that multiple entities are processed within a single database transaction.
- Request/Response Structure Update: save_*_request messages now accept a std::vector<entity>, and save_*_response messages return a single {bool success, std::string message} outcome. Similarly, delete_*_request messages accept batch input via std::vector, and delete_*_response messages return a single atomic outcome.
- Protocol Version Increment: The communication protocol version has been updated to 46.0 to reflect these breaking changes in the wire format for save operations.
- Client-Side Adaptations: All relevant Qt client-side callers across ores.qt have been updated to align with the new protocol field names and access patterns.
- New save_result.hpp: Introduced a new header file defining a generic save_result struct and helper functions for handling batch operation outcomes.
This pull request significantly enhances data integrity and performance for batch delete operations across multiple core services. Previously, batch deletes were non-atomic, leading to potential partial data removal if an error occurred mid-process. The changes introduce atomic batch deletion by leveraging SQL's WHERE IN clause, ensuring that either all items in a batch are deleted or none are. This refactoring also includes the removal of dead code, streamlining the codebase.
Highlights:
- Batch Delete Atomicity: Implemented atomic batch delete operations across 23 entities in four modules (ores.dq, ores.refdata, ores.trading, ores.iam) by replacing individual delete calls within loops with a single DELETE FROM table WHERE col IN (…) SQL query.
- Code Cleanup: Removed the unused save_result.hpp header file and all its includes from various protocol headers and message handler implementation files, reducing build dependencies and improving code hygiene.
- Architectural Pattern: Introduced a consistent 3-layer pattern for batch deletes: adding remove(const std::vector<std::string>& codes) overloads in repositories, plural remove_X methods in services, and updating message handlers to utilize these new atomic service calls.
- Temporal Guard Handling: Addressed special cases for IAM module entities (tenant_type, tenant_status) by incorporating a temporal guard ("valid_to"_c == max.value()) into their batch delete queries to ensure historical data integrity.
POSTPONED Add party level currency and country restrictions code
At present a party can use all currencies and all countries. In reality we normally want to restrict this at the party level. We won't be able to do a full implementation of this right now but it is a good idea to put in the framework so that we start to get a feel for how to work with RLS.
This pull request significantly enhances the reference data management system by introducing party-specific visibility for currencies and countries. It establishes a robust framework for granular control over which reference data elements are accessible to different parties, addressing a limitation where all such data was previously tenant-wide. The changes span the entire application stack, from database schema and generated C++ code to service-level filtering, ensuring a comprehensive and well-integrated solution.
Highlights:
- New Party-Visibility Junction Tables: Introduced ores_refdata_party_currencies_tbl and ores_refdata_party_countries_tbl to control which currencies and countries are visible to specific parties, moving from tenant-wide visibility to per-party control.
- Full Stack Codegen: Generated the complete domain, repository, service, and test layers for both new entities using codegen models, ensuring consistency and reducing manual effort.
- Service Integration: Integrated filtering logic into existing currency_service and country_service to leverage the new junction tables, adding list_currencies_for_party and list_countries_for_party methods.
- Bitemporal Support: Implemented bitemporal functionality for the new junction tables, including valid_from and valid_to columns, versioning, and soft-delete rules.
POSTPONED Add trade import mapping dialog to Qt UI code
Add a mapping dialog to the Qt UI for importing ORE portfolio XML files. The dialog should allow users to:
- Select an ORE portfolio XML file.
- Preview the trades that will be imported (count, types, counterparties).
- Select the ORES book to import trades into.
- Map ORE
CounterPartynames to ORES counterparties (or auto-create). - Review and confirm the import.
This dialog should be accessible from the book list window toolbar when a book is selected (similar to the currency import button on the currency list window).
Files to modify:
BookMdiWindow.hpp/cpp- add import toolbar action- New
ImportTradeDialog.hpp/cpp- the mapping and preview dialog BookController.hpp/cpp- wire up the import action
Acceptance criteria:
- Import button is visible and enabled when a book is selected.
- Dialog shows trade preview with counterparty mapping.
- Successful import creates trades in the selected book.
- Trades appear in the trade list after import.
AI Generated Sprint Summary
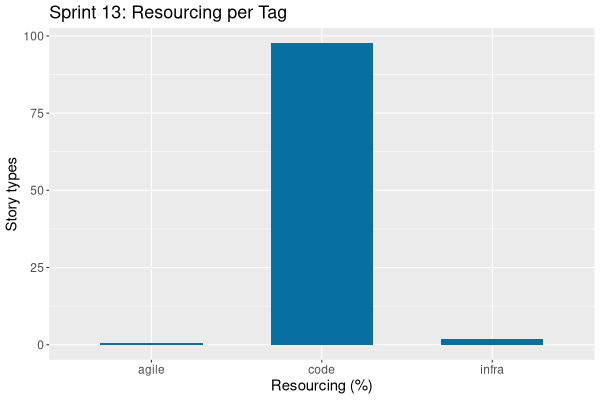
# **ORE Studio Sprint 13 – Release Notes** *February 2026* Sprint 13 delivered the foundational **trade and scheduling infrastructure** while simultaneously maturing the platform's security model, UI, and reference data layer. The sprint's centrepiece was the introduction of **account-party management**, tying IAM accounts to specific parties and establishing the groundwork for party-scoped access control across the entire system. On the trading side, we completed the full **scheduler subsystem** — binary protocol, scheduling engine, and message queue — and conducted the critical analysis required to map ORE trade data into the platform's model. The **Qt UI underwent a comprehensive overhaul**: all detail dialogs are now tabbed, toolbars have been removed for a cleaner aesthetic, and a new **portfolio explorer** provides a hierarchical view of books and trades. Named environments were added to the connection manager, significantly improving the developer workflow. This sprint marks a turning point from reference data foundations toward an operational trading platform, with the first scheduling and messaging primitives now in place and trade import firmly on the critical path for Sprint 14. --- ## ✅ **Highlights** - Completed full **account-party management and login support** (13h 43m), enabling party-scoped authentication. - Delivered **scheduling infrastructure**: scheduler binary protocol, scheduling support, and a message queue. - Overhauled the **Qt UI**: all detail dialogs are now tabbed, toolbars removed, and a portfolio explorer added. - Added **named environments** to the connection manager for one-click host/port selection. - Completed **ORE trade import mapping analysis** as groundwork for the upcoming import dialog. ## 🛠️ **Key Improvements** ### **Trading & Scheduling** - Analysed ORE trade import mapping requirements. - Added scheduler binary protocol and scheduling support. - Added a message queue for async processing. - Added batch support for saves and deletes (in progress at sprint close). ### **Security & IAM** - Added account-party management with login support. - Fixed provenance: `performed_by` and `modified_by` stamping across all write paths. ### **Qt UI & UX** - All detail dialogs converted to tabbed layout. - Toolbars removed from detail dialogs. - Added portfolio explorer with breadcrumb scope and book/trade hierarchy. - Added named environments to connection manager. - Minor connection browser improvements. ### **Reference Data** - Added rounding type entity. - Enhanced currency taxonomy and renamed currency asset classes. - Books, portfolios, and trades are now party-specific. ### **Architecture** - Merged FSM into DQ component. - Added session data plotting. ## ⚠️ **Known Issues & Postponed** - **Add party level currency and country restrictions** – Deferred to Sprint 14; some analysis work completed. - **Add trade import mapping dialog to Qt UI** – Deferred to Sprint 14; 6h 07m of implementation started. ## 📊 **Time Summary** - **Total effort**: 72h 13m - **Code**: 97.6% | **Infra**: 1.8% | **Agile**: 0.6% - Top tasks: Account-party management (13h 43m), Scheduling support (6h 48m), Trade import dialog (6h 07m), Remove toolbars (5h 57m), Batch saves/deletes (5h 32m), Portfolio explorer (5h 19m) --- *Next sprint: Continue trade import UI, party-level restrictions, and begin further trading domain features.* ---
Footer
| Previous: Sprint Backlog 12 |