Sprint Backlog 14
Sprint Mission
- Work on messaging infrastructure.
Stories
Active
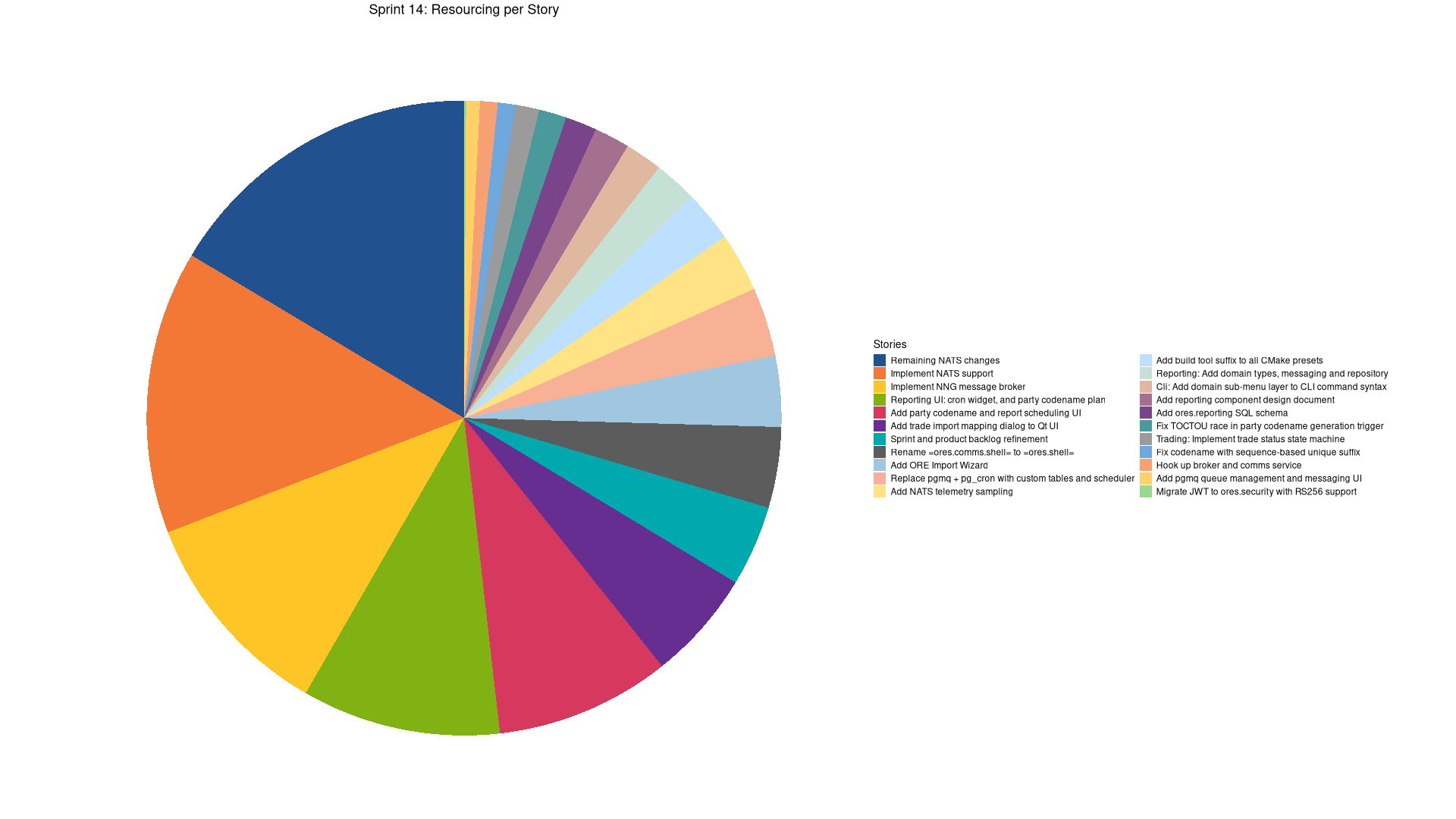
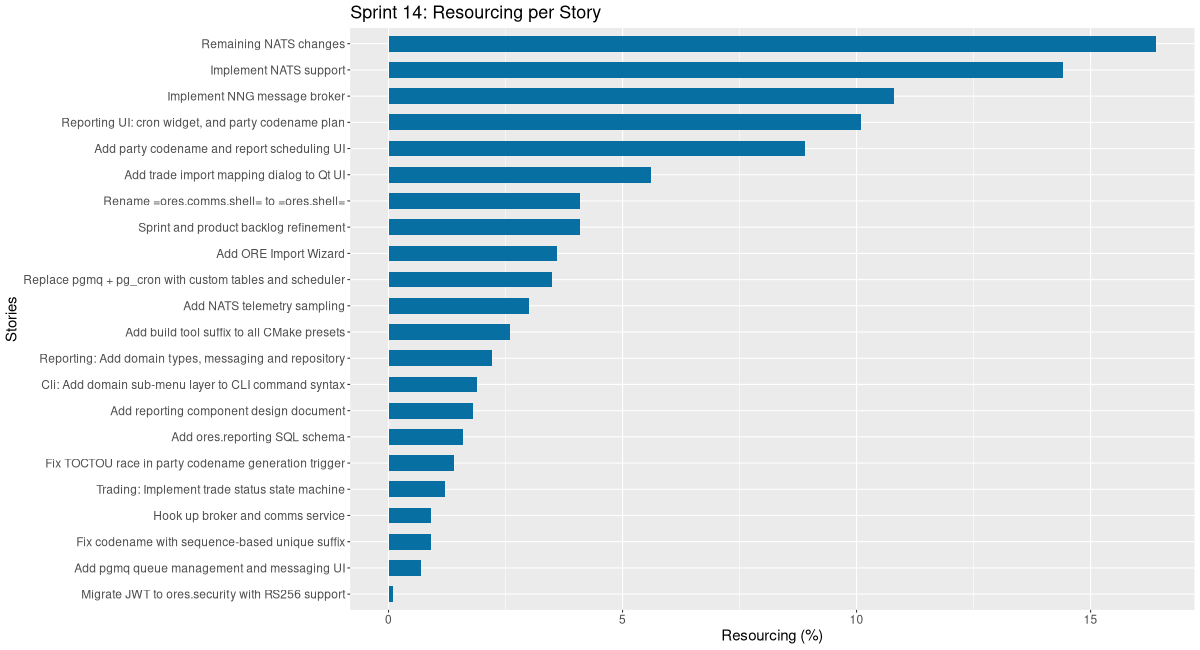
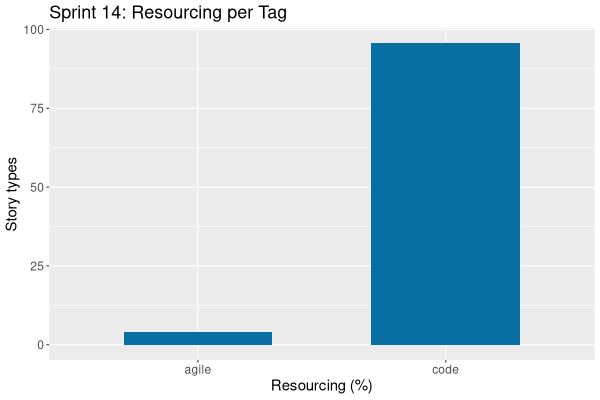
| Tags | Headline | Time | % |
|---|---|---|---|
| Total time | 0:00 | 0.0 |
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 82:38 | 100.0 | |||
| Stories | 82:38 | 100.0 | |||
| Active | 82:38 | 100.0 | |||
| agile | Sprint and product backlog refinement | 3:23 | 4.1 | ||
| code | Add ORE Import Wizard | 3:00 | 3.6 | ||
| code | Add reporting component design document | 1:30 | 1.8 | ||
| code | Add ores.reporting SQL schema | 1:20 | 1.6 | ||
| code | Reporting: Add domain types, messaging and repository | 1:50 | 2.2 | ||
| code | Trading: Implement trade status state machine | 0:59 | 1.2 | ||
| code | Cli: Add domain sub-menu layer to CLI command syntax | 1:35 | 1.9 | ||
| code | Add pgmq queue management and messaging UI | 0:34 | 0.7 | ||
| code | Reporting UI: cron widget, and party codename plan | 8:19 | 10.1 | ||
| code | Add party codename and report scheduling UI | 7:19 | 8.9 | ||
| code | Replace pgmq + pg_cron with custom tables and scheduler | 2:54 | 3.5 | ||
| code | Fix TOCTOU race in party codename generation trigger | 1:10 | 1.4 | ||
| code | Migrate JWT to ores.security with RS256 support | 0:07 | 0.1 | ||
| code | Implement NNG message broker | 8:55 | 10.8 | ||
| code | Add build tool suffix to all CMake presets | 2:10 | 2.6 | ||
| code | Fix codename with sequence-based unique suffix | 0:45 | 0.9 | ||
| code | Hook up broker and comms service | 0:47 | 0.9 | ||
| code | Implement NATS support | 11:55 | 14.4 | ||
| code | Rename ores.comms.shell to ores.shell |
3:25 | 4.1 | ||
| code | Add NATS telemetry sampling | 2:30 | 3.0 | ||
| code | Add trade import mapping dialog to Qt UI | 4:39 | 5.6 | ||
| code | Remaining NATS changes | 13:32 | 16.4 |
COMPLETED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
COMPLETED Add ORE Import Wizard code
This pull request delivers a robust ORE data import solution, enabling users to seamlessly bring ORE directory structures and their contained financial data into OreStudio. It provides a guided, multi-step wizard experience, backed by sophisticated backend logic to process, organize, and integrate the data while handling potential conflicts and ensuring data integrity.
Highlights:
- New ORE Import Wizard: Introduced a comprehensive 7-page QWizard (OreImportWizard) to facilitate the import of ORE directory data into OreStudio, covering directory scanning, hierarchy building, and trade import.
- Backend Logic for ORE Data Processing: Implemented core logic in the ores.ore layer, including ore_directory_scanner for classifying files, ore_hierarchy_builder for constructing portfolio/book hierarchies with intelligent naming and deduplication, and ore_import_planner for generating a complete import plan based on user choices and existing data.
- Enhanced UI Integration: Integrated the ORE Import Wizard into the Qt UI, accessible via the 'File' menu and a new toolbar button in the Portfolio Explorer. The wizard features asynchronous scanning, dynamic fetching of currencies and portfolios, and batched trade imports with live progress reporting.
- Intelligent Data Handling: Added features for detecting currency and portfolio XML files by root element, stripping configurable path segments for cleaner hierarchy, human-readable naming conventions for portfolios and books, and flexible re-import modes (add new trades only or create new temporal versions).
Merged stories:
ORE Importer: portfolio and trade support
Now that we have the basics for trades, books and portfolios, we can do a very basic ORE importer:
- point it to the samples directory;
- for each folder, if it has subfolders, create a portfolio. If it contains the trades file, make it a book.
- add each trade in the trade file.
Notes:
- users should be able to choose top-level portfolio to import it into. counterparty.
COMPLETED Add reporting component design document code
This pull request establishes the foundational design for a new reporting component, ores.reporting, within ORE Studio. It provides a detailed blueprint for how reports will be defined, scheduled, and executed, focusing on a robust domain model, clear state transitions, and integration with existing scheduling and analytics services. The design aims to support various report types, starting with risk reports, and lays the groundwork for future enhancements like distributed execution and advanced output handling.
Highlights:
- New Component Design: Introduced the comprehensive design specification for ores.reporting, a new domain component in ORE Studio responsible for defining and executing analytical reports.
- Core Concepts Defined: Detailed the domain model, including report_type enumeration, report_definition (template), report_instance (single execution), and risk_report_config for type-specific settings.
- Dual State Machines: Designed distinct state machines for report_definition (draft, active, suspended, archived) and report_instance (pending, running, completed, failed, cancelled) to manage their lifecycles.
- Scheduler Integration: Outlined the integration with ores.scheduler for cron-based recurring execution and event-driven instance creation, leveraging pg_cron.
- Extensibility and Future Plans: Addressed future extensibility with planned support for ores.grid for distributed execution and identified open questions regarding output storage, execution environment, concurrency, and cancellation.
COMPLETED Add ores.reporting SQL schema code
This pull request significantly expands the database capabilities by introducing a dedicated ores.reporting schema. It provides the foundational tables, functions, and triggers necessary to define, schedule, execute, and track various reports, particularly focusing on financial risk analytics. The new schema incorporates advanced features like FSM-driven lifecycle management, configurable concurrency policies, and granular risk parameter settings, all while ensuring data integrity and security through robust validation and Row-Level Security. This change enables a structured and scalable approach to reporting within the system.
Highlights:
- New Reporting Schema: Introduced a comprehensive SQL schema for the ores.reporting component, enabling robust report management and execution.
- Report Definitions and Instances: Added tables for report_definitions (templates with FSM lifecycle, cron schedules) and report_instances (individual execution records with FSM lifecycle).
- Concurrency and Report Types: Implemented enum tables for concurrency_policies (skip, queue, fail) and report_types (risk, grid) to provide flexible control over report execution and categorization.
- Risk Report Configuration: Included a detailed risk_report_configs table to store ORE analytics parameters (NPV, cashflow, XVA, VaR, SIMM) and temporal junction tables for portfolio and book scoping.
- Lifecycle Management and Notifications: Integrated Finite State Machine (FSM) population scripts for both report definition and instance lifecycles, along with NOTIFY triggers on all tables for real-time UI updates.
- Row-Level Security (RLS): Applied RLS policies across reporting tables to ensure tenant and party isolation, enhancing data security and multi-tenancy support.
- Schema Validation Integration: Registered the new ores_reporting_ component prefix within the schema validator to ensure proper recognition and management of the new database objects.
COMPLETED Reporting: Add domain types, messaging and repository code
This pull request establishes a foundational reporting subsystem within the ores project. It introduces a new C++ component, ores.reporting, complete with its core domain models, data access layers, and messaging protocols. This enables the system to manage various aspects of reporting, including defining report types, handling concurrency policies for report execution, scheduling report definitions, and tracking individual report instances.
Highlights:
- New Reporting Component: Introduced a new C++ component, ores.reporting, to manage all aspects of report generation and tracking.
- Core Domain Types: Added foundational domain types: report_type, concurrency_policy, report_definition, and report_instance.
- Messaging Protocols: Implemented messaging protocols for CRUD operations and history retrieval for all four new reporting entities, registering 32 new message types in ores.comms.
- Repository Layer: Developed a repository layer for each reporting entity to handle data persistence and retrieval.
- Code Generation Models: Included code generator models under projects/ores.codegen/models/reporting/ for automated generation of related code artifacts.
- Build System Integration: Integrated the new ores.reporting component into the project's CMake build system.
COMPLETED Trading: Implement trade status state machine code
This pull request significantly enhances the trade management system by introducing a formal state machine for tracking trade statuses and a detailed taxonomy for classifying trade activities. These changes provide a more structured and robust framework for managing trade lifecycles, ensuring data integrity through enforced state transitions and improving the granularity of event tracking for reporting and analysis. The update also includes essential bug fixes to improve build stability and data isolation.
Highlights:
- Trade Status State Machine Implementation: Introduced a robust trade status Finite State Machine (FSM) within the ores.dq module, defining states (new, live, expired, cancelled) and transitions (initial booking, confirm, cancel, expire) to manage the operational lifecycle of trades. This FSM is now integrated into the ores.trading module to enforce valid state changes.
- Activity Type Taxonomy: Replaced the previous lifecycle_events concept with a comprehensive activity_type taxonomy. This new system classifies trade events into categories like 'new activity', 'lifecycle event', 'misbooking', 'valuation change', and 'cancellation', providing detailed P&L attribution and reporting capabilities. Each activity type can optionally map to an FpML event type and/or an FSM transition.
- Database Schema and C++ Domain Model Updates: Updated the database schema to include new tables for FpML event types and activity types, and modified the ores_trading_trades_tbl to incorporate activity_type_code and status_id columns. Corresponding C++ domain objects, mappers, and repositories were added or updated across ores.dq and ores.trading to support these new structures.
- Trade Status Resolution Service: Implemented a trade_status_service::resolve_status() function that validates and applies FSM transitions. This service ensures that trade status changes are only permitted if they correspond to a valid FSM transition linked to the activity type and are allowed from the trade's current state.
- Bug Fixes and Refactoring: Addressed a bug in the reflectcpp portfile by removing an incorrect bson-1.0 to bson rename, which had prevented sqlgen from building. Also, corrected cross-tenant data leakage issues in ores.refdata repositories by adding tenant_id to read/delete WHERE clauses.
COMPLETED Cli: Add domain sub-menu layer to CLI command syntax code
This pull request significantly refactors the ORE Studio CLI's command structure by introducing a new domain layer. This architectural change organizes commands into logical categories such as 'refdata', 'iam', 'dq', and 'variability', enhancing the clarity and scalability of the CLI. The updated syntax requires users to specify a domain before an entity and operation, providing a more structured and intuitive command-line experience.
Highlights:
- New CLI Command Syntax: Introduced a new domain sub-menu layer to the CLI command syntax, changing it from 'ores.cli ' to 'ores.cli '.
- New Domain Categories: Defined four new top-level domains: 'refdata', 'iam', 'dq', and 'variability', to logically group related entities and commands.
- Core Parser Refactoring: Refactored the core CLI argument parser to support the new domain-prefixed command structure, including new domain-specific parsers.
- Documentation and Test Updates: Updated all existing entity parsers, CLI documentation examples, and test cases to conform to the new domain-based syntax.
COMPLETED Add pgmq queue management and messaging UI code
This pull request delivers a robust and user-friendly message queue management solution. It integrates a new message queuing subsystem into the core application, enabling comprehensive control and monitoring of pgmq queues. The changes span database schema, communication protocols, backend service logic, and a rich graphical user interface, providing a complete end-to-end feature for managing message queues.
Highlights:
- New Message Queue (MQ) Subsystem: Introduced a complete MQ subsystem with new protocol message types (0xB000-0xB013) for queue management and messaging operations, including creation, deletion, purging, sending, reading, popping, and deleting messages.
- Queue Metrics and Monitoring: Implemented a time-series database schema (ores_mq_metrics_samples_tbl) for storing pgmq queue metrics, along with a pg_cron job (ores_mq_scrape_metrics_fn) to automatically scrape and persist these metrics every minute. The pg_cron job is initialized at service startup.
- Comprehensive Queue Monitor UI: Developed a full-featured Qt-based UI for monitoring and managing pgmq queues. This includes a ClientQueueModel for live merged views of queue metadata and metrics, a QueueMonitorMdiWindow with actions for queue CRUD and charting, a QueueDetailDialog for publishing and interacting with messages, and a QueueChartWindow for visualizing time-series queue depth and total messages sent.
- Protocol Version Update: Updated the communication protocol to version 46.3 to reflect the addition of the new MQ subsystem and its associated message types.
COMPLETED Reporting UI: cron widget, and party codename plan code
This pull request significantly enhances the reporting capabilities of the ORE Studio by introducing a full-fledged Qt user interface for managing report configurations and instances. It also lays the groundwork for robust, isolated event processing through a new party codename design, ensuring secure and scalable report scheduling. The changes span across UI components, backend services, and core code generation logic, providing a more intuitive and powerful experience for defining and monitoring reports.
Highlights:
- Reporting UI Integration: Introduced a comprehensive Qt UI for managing report types, concurrency policies, report definitions, and report instances, including dedicated MDI windows, detail dialogs, and history views.
- Cron Expression Management: Added interactive CronExpressionWidget and CronEditorDialog for intuitive creation and editing of cron schedules within the UI.
- Report Scheduling Backend: Implemented backend message handlers for scheduling and unscheduling report definitions, leveraging pg_cron for job management and pgmq for event queueing.
- Party Codename Design: Introduced a detailed design plan for adding a unique, human-readable codename to the party entity, primarily for per-party pgmq queue isolation and internal identification.
- Qt Codegen Enhancements: Extended the code generation system to support optional timestamp fields, UUID handling, and improved integer casting in Qt models.
- Tenant Provisioning Wizard Update: Integrated new steps into the tenant provisioning wizard to allow selection and automatic creation of initial report definitions.
- Iconography Expansion: Added new icons for 'Arrow Trending', 'Chart Multiple', and 'Tasks App' to enhance UI clarity for trading, reporting, and job management.
COMPLETED Add party codename and report scheduling UI code
This pull request significantly enhances the system's multi-tenancy and reporting capabilities. It introduces a unique codename for each party, which is leveraged for isolated messaging queues and improved UI representation. The report scheduling interface has been refined with better data handling, live updates, and a more robust user experience including mandatory change reasons for modifications. A major architectural improvement is the centralized handling of session context and authentication stamping, ensuring consistent and secure data manipulation across various services. Additionally, the message queue monitoring and background job scheduling mechanisms have been updated to respect party-level isolation, leading to a more secure and reliable system.
Highlights:
- Party Codename Implementation: Introduced a globally unique adjective_noun codename for each party, automatically generated by a SQL trigger using ores_utility_generate_whimsical_name_fn(). This codename is now used as a prefix for per-party PGMQ queues ({codename}_report_events) to ensure tenant isolation outside of Row-Level Security (RLS). The codename is exposed in the Qt party list (hidden by default) and as a read-only field in the party detail dialog.
- Enhanced Report Scheduling UI: Improved the report definition UI by fixing a missing party_id during saving, adding event subscriptions for live updates, and implementing client-side calculation of the 'Next Fire' column from cron expressions. Edits to report definitions now trigger a change reason dialog.
- Centralized Session Context Propagation & Authentication Stamping: Implemented comprehensive session context propagation (actor, tenant, party) through raw SQL execute functions, enforcing service account constants. A new C++23 requires-expression template helper, stamp_auth, was added to tenant_aware_handler to centralize the stamping of authentication fields (modified_by, performed_by, tenant_id, party_id) across various message handler subsystems.
- MQ Queue Monitoring Improvements: Fixed queue visibility in the MQ queue monitor to display only queues relevant to the currently selected party (app.current_party_id), thereby enforcing party-scoped isolation. New party-scoped SQL functions (ores_mq_list_party_queues_fn, ores_mq_metrics_party_fn, ores_mq_metric_samples_fn) were introduced to manage this isolation.
- Idempotent MQ Metrics Scrape Job Registration: The MQ metrics scrape job registration was made idempotent, preventing duplicate job creation on service startup. The job now correctly uses a party-scoped context for querying existing job definitions, ensuring proper RLS policy adherence.
COMPLETED Replace pgmq + pg_cron with custom tables and scheduler code
This pull request represents a significant architectural shift, moving away from reliance on external PostgreSQL extensions for message queuing and job scheduling. By implementing these functionalities natively within custom tables and an in-process C++ scheduler, the system gains tighter integration with its RLS architecture, improved control over data structures, and a more unified codebase. This change impacts core messaging and scheduling mechanisms, requiring updates across various components including the communication protocol, UI, and reporting services.
Highlights:
- Extension Removal: The external PostgreSQL extensions pgmq and pg_cron have been entirely removed from the system, replaced by native infrastructure.
- Custom Message Queue (MQ) Tables: New custom ores_mq_* tables (mq_queues, mq_messages, mq_message_archive, mq_queue_stats, mq_channel_messages stub) have been introduced, offering three scope levels (party, tenant, system) and two queue types (task, channel) with native Row-Level Security (RLS).
- In-Process C++ Scheduler: A new in-process C++ scheduler loop (scheduler_loop) has been implemented using boost::asio::steady_timer, replacing the previous pg_cron jobs. It supports sql_action_handler for executing SQL and mq_action_handler for sending MQ messages.
- Scheduler Job Instances: A new TimescaleDB hypertable, ores_scheduler_job_instances_tbl, now stores the execution history for scheduled jobs, replacing cron.job_run_details.
- Updated MQ Protocol and Service: The ores.mq component has been significantly updated with new domain types, queue/message/stats repositories, and an mq_service facade. The communication protocol has been bumped to v48.0 to reflect these breaking changes.
- UI Updates: The ores.qt MQ Monitor now displays scope_type, queue_type, description, pending_count, and processing_count, with codename-based filtering removed. Report scheduling in ores.reporting now uses the new mq_service.
COMPLETED Fix TOCTOU race in party codename generation trigger code
This pull request enhances the robustness of the database by resolving a concurrency issue in the party codename generation logic. By introducing an advisory lock, it prevents race conditions that previously led to data integrity violations and unstable automated tests.
Highlights:
- Race Condition Fix: Addressed a Time-of-Check-to-Time-of-Use (TOCTOU) race condition that could lead to unique constraint violations during concurrent party codename generation.
- Concurrency Control: Implemented pg_advisory_xact_lock within the BEFORE INSERT trigger to serialize the codename generation process, ensuring uniqueness.
- CI Stability: Resolved intermittent CI failures caused by duplicate key errors in parallel test runs.
COMPLETED Migrate JWT to ores.security with RS256 support code
This pull request significantly enhances the security and scalability of the system's authentication mechanism by centralizing JWT handling and introducing robust asymmetric encryption. It enables secure, distributed authentication across services, which is crucial for the upcoming NNG broker architecture. Additionally, it addresses a critical race condition in party codename generation, improving system stability.
Highlights:
- JWT Infrastructure Migration: The JWT authentication infrastructure has been moved from the private ores.http module to the shared ores.security module, making it accessible across all services.
- RS256 Asymmetric Signing Support: Asymmetric RS256 signing and verification have been implemented, allowing the IAM service to mint tokens with a private key while other services verify them using only a public key.
- Extended JWT Claims: The jwt_claims structure has been extended to include tenant_id and party_id fields, essential for distributed service authentication.
- IAM Login Response Update: The IAM service now mints an RS256 JWT upon successful login and includes it in the login_response, providing a token for subsequent authenticated requests.
- Protocol Version Bump: The communication protocol major version has been incremented to 49.0 to reflect the breaking change of adding the JWT field to the login_response.
- TOCTOU Race Condition Fix: A Time-of-Check to Time-of-Use (TOCTOU) race condition in the party codename generation trigger has been fixed by introducing a pg_advisory_xact_lock.
COMPLETED Implement NNG message broker code
NNG message broker — JWT in frames, broker protocol, routing, and service registration:
This pull request introduces a foundational message broker architecture using NNG, designed to centralize message routing between client-facing services and backend components. It significantly enhances security and scalability by embedding JWT tokens directly into message frames for independent service validation and provides a robust mechanism for services to dynamically register their message handling capabilities with the broker. This change paves the way for a more distributed and resilient system.
Highlights:
- NNG-based Message Broker Introduction: A new standalone ores.mq.broker executable has been introduced, implementing an NNG-based message broker architecture to route binary protocol frames between clients and registered backend services.
- JWT in Message Frames: The core protocol (v50.0) now embeds JWT tokens directly within every message frame via a new jwt_size field, allowing services to independently validate client identity without a central session store. The CRC calculation has been updated to include these JWT bytes.
- Broker Protocol and Service Registration: New broker-specific message types (register_service_request/response, token_refresh_request/response) have been added, enabling services to self-register their handled message type ranges with the broker and request token refreshes.
- Auth Session Refactor for JWT: The auth_session_service has been refactored to support JWT validation, including a new jwt_validator_fn and a secondary session_id_index_ for efficient session lookup by JWT session_id claims.
- Service Self-Registration: The ores.comms.service now includes logic to connect to the broker backend at startup and register all its handled message type ranges, integrating it into the new brokered communication model.
Implement a NNG-based broker:
This pull request significantly refactors the application's integration with the NNG message broker. It introduces a dedicated service runner to manage broker communication, centralizing the logic for registration and message processing. This change enhances modularity, enables asynchronous message handling, and improves the overall robustness and scalability of the messaging infrastructure by isolating NNG-specific operations.
Highlights:
- New NNG Service Runner: Introduced a new nng_service_runner class to encapsulate the logic for registering with the NNG broker and handling message reception and dispatching in a dedicated, persistent loop.
- Refactored Broker Integration: The application.cpp was refactored to utilize the new nng_service_runner, moving the broker registration and message processing into a separate thread for improved concurrency and separation of concerns.
- Asynchronous Message Dispatching: Implemented an asynchronous adapter within the application.cpp to dispatch raw NNG messages through the existing message_dispatcher using boost::asio::co_spawn, allowing for non-blocking message handling.
- Enhanced Error Handling: Added logic to generate minimal error response frames when NNG message parsing fails, ensuring robust communication with the broker.
- Message Dispatcher Access: Exposed the shared message_dispatcher via a new dispatcher() method in the server class, enabling external components like the NNG service runner to utilize the same message handling registry.
COMPLETED Add build tool suffix to all CMake presets code
This pull request refactors the CMake preset configuration to explicitly include the build tool (Ninja or Make) in all preset names, enhancing clarity and flexibility. It introduces dedicated hidden presets for Ninja and Make to centralize generator settings and specific build tool options, such as disabling colored output for Make. This change also expands build options for Linux and macOS to include both Ninja and Make, while standardizing Windows builds on Ninja. Additionally, the PR simplifies the parallel build configuration by removing automatic detection from 'CMakeLists.txt' and updates all internal documentation and skill instructions to align with these new conventions.
Highlights:
- CMake Preset Renaming: All CMake presets have been renamed to explicitly include the build tool (Ninja or Make) in their names, following the pattern {platform}-{compiler}-{buildtype}-{tool}.
- Build Tool Specific Presets: Hidden 'ninja' and 'make' presets were introduced to centralize generator settings and specific build tool configurations, such as disabling colored diagnostics for Make.
- Expanded Platform Support: Linux and macOS now support both Ninja and Make variants, while Windows builds are standardized on Ninja only.
- Parallel Build Simplification: Automatic parallel build level detection was removed from 'CMakeLists.txt', deferring this configuration to user environment variables or build tool defaults.
- Documentation Updates: All relevant documentation and skill files have been updated to reflect the new CMake preset naming conventions and revised parallel build instructions.
COMPLETED Fix codename with sequence-based unique suffix code
This pull request addresses a critical race condition in the codename generation process for parties, which was leading to database unique key violations during batch inserts. By fundamentally changing how unique codenames are generated, it ensures data integrity and allows for the reintroduction of efficient batch insert operations, significantly improving performance and reliability.
Highlights:
- Codename Race Condition Fix: Resolved an intermittent 'duplicate key' violation in codename generation caused by a race condition in the ores_refdata_parties_codename_uniq_idx trigger, which previously used a NOT EXISTS check and an ineffective advisory lock.
- Sequence-Based Suffix Implementation: Replaced the problematic advisory lock and NOT EXISTS loop with a new sequence-based suffix mechanism to ensure unique codenames.
- New Utility Function: Introduced ores_utility_to_base26_fn(bigint) to encode sequence values into lowercase base-26 strings, satisfying codename regex constraints.
- New Database Sequence: Created ores_refdata_party_codename_seq to provide unique, MVCC-independent sequence values for codename suffixes.
- Simplified Codename Trigger: Updated the ores_refdata_parties_insert_fn trigger to append the base-26 encoded sequence value to whimsical names, ensuring uniqueness for each row in a batch.
- Reinstated Batch Inserts: Reverted party_repository::write(vector) to use proper batch inserts, as the previous workaround of sequential single-row inserts is no longer necessary due to the new codename generation logic.
COMPLETED Rename currency asset classes code
Rationale: implemented in previous sprint.
We should avoid the term "asset classes" unless it is used in the usual asset class context. Many of the values are not really what one things of asset classes.
COMPLETED Alert for unsaved modified entities code
Rationale: implemented in previous sprint.
If a user changes an entity but does not save it, we should alert the user. Also, we probably should add a cancel button to all detail dialogs.
CANCELLED Hook up broker and comms service code
We have introduced the broker but we did not validate that the infrastructure works as expected.
COMPLETED Implement NATS support code
NNG seems like a lot of work. Let's try NATS first.
This pull request represents a significant architectural shift, replacing the custom binary communication protocol with NATS for all inter-service and client-server messaging. This migration moves the system towards a more standard, scalable, and maintainable messaging infrastructure, facilitating the decomposition of the monolithic service into independent microservices. The change impacts core communication, authentication, and eventing mechanisms across the entire application.
Highlights:
- Protocol Migration: Replaced the entire ores.comms binary-protocol stack (SSL/ASIO transport, NNG broker) with cnats request/reply messaging, resulting in a deletion of ~107k lines of old code and addition of ~20k lines of new NATS-idiomatic code.
- Microservice Architecture: Introduced a new ores.nats component with a clean
nats::service::clientinterface and wired all 10 domain services (iam, variability, refdata, assets, trading, dq, reporting, scheduler, synthetic, telemetry) to NATS with full CRUD handlers, enabling a decomposed microservice architecture.- Client and Shell Migration: Re-enabled ores.comms.shell and ores.http.server on the new NATS transport, and migrated the ores.qt GUI client to use the new messaging system.
- NATS Subject Management: Added NATS subject prefixes (ores.{tier}.{instance}) for environment isolation and fixed a _INBOX.* reply-subject prefixing bug that previously broke all request/reply functionality.
- Scheduler Serialization: Added rfl::Reflector<cron_expression> for scheduler private-member serialization, improving data handling for scheduled tasks.
Merge MQ into nats:
This pull request undertakes a significant architectural shift by transitioning the project's messaging queue infrastructure from a PGMQ-based system (ores.mq) to NATS JetStream, integrated within the ores.nats module. The core of this change is the introduction of a robust jetstream_admin service, enabling comprehensive management of JetStream streams and consumers through a clean, C++-native interface. This migration necessitated updates across the Qt client, which now directly interacts with JetStream for queue monitoring and message handling, and led to the complete deprecation and removal of the ores.mq library.
Highlights:
- Messaging System Migration: Migrated the internal queue management system from ores.mq (which used PGMQ) to ores.nats, leveraging NATS JetStream for durable messaging and stream processing.
- JetStream Administration API: Introduced a new jetstream_admin service class within ores.nats that wraps the cnats JetStream management API, providing functionalities like listing streams and consumers, peeking at messages, publishing, and deleting messages, all while abstracting cnats types behind an opaque void*.
- New JetStream Domain Types: Added three new domain types: stream_info, consumer_info, and stream_message, which replace the old queue_definition and queue_stats types from ores.mq to represent JetStream entities.
- Qt Queue Monitor Update: The Qt Queue Monitor application has been updated to directly utilize the new JetStream administration capabilities for displaying stream lists, consumer counts, and enabling message peek, publish, and delete operations.
- Removal of ores.mq Library: The ores.mq header-only library, which previously handled PGMQ interactions, has been entirely removed from the project as it is no longer needed.
- Queue Chart Window Simplification: The Qt Queue Chart window has been simplified to a placeholder, awaiting future integration with TimescaleDB for historical NATS JetStream statistics.
COMPLETED Rename ores.comms.shell to ores.shell code
- rename ores.comms.shell to just ores.shell: done.
- rename ores.nats to ores.messaging: decided against it after chat with Claude.
- rename protocol documents to messaging.
- Clean up NATS build issues
This pull request addresses critical CI failures and updates extensive documentation following a recent migration to NATS JetStream messaging. It ensures that service configuration tests accurately reflect the opt-in nature of logging and provides comprehensive, subject-based protocol references for all services, enhancing clarity and maintainability of the system's communication architecture.
Highlights:
- CI Test Fixes: Fixed 10 service configuration parser tests to correctly handle opt-in logging, ensuring tests pass when logging is explicitly enabled or absent by default.
- NATS Documentation Rewrite: Rewrote NATS messaging protocol documentation across all 10 services, replacing outdated binary protocol references with subject-based ones and introducing new component documentation for clarity and accuracy.
COMPLETED Add NATS telemetry sampling code
- add nats.service that stores samples, etc. Discuss with Claude if we should rename nats to messaging or not. Having a messaging service is a bit confusing as it does not do core messaging at all. Maybe we should not call this "service". or maybe we should add it to telemetry.
POSTPONED Add trade import mapping dialog to Qt UI code
Add a mapping dialog to the Qt UI for importing ORE portfolio XML files. The dialog should allow users to:
- Select an ORE portfolio XML file.
- Preview the trades that will be imported (count, types, counterparties).
- Select the ORES book to import trades into.
- Map ORE
CounterPartynames to ORES counterparties (or auto-create). - Review and confirm the import.
This dialog should be accessible from the book list window toolbar when a book is selected (similar to the currency import button on the currency list window).
Files to modify:
BookMdiWindow.hpp/cpp- add import toolbar action- New
ImportTradeDialog.hpp/cpp- the mapping and preview dialog BookController.hpp/cpp- wire up the import action
Acceptance criteria:
- Import button is visible and enabled when a book is selected.
- Dialog shows trade preview with counterparty mapping.
- Successful import creates trades in the selected book.
- Trades appear in the trade list after import.
COMPLETED Remaining NATS changes code
This pull request introduces several key enhancements and fixes related to NATS multi-tenancy, RBAC, and LEI entity handling. It streamlines tenant provisioning, ensures proper data scoping, enhances entity summary capabilities, and improves logging.
Highlights:
- Tenant Provisioning: Automated system party creation for new tenants, granting tenant admins immediate party context in JWTs. Also, a system bootstrap mode flag has been seeded to trigger the provisioning wizard on first login.
- Tenant UUID: Server-side UUID generation in tenant_handler::save() addresses cases where the client omits it.
- RBAC/RLS: The account_handler is fixed to ensure all methods use make_request_context, scoping DB queries to the requesting user's tenant.
- LEI Entity Handler: The lei_entity_handler::summary() is implemented, calling SQL functions instead of inline SQL.
- SQL Functions: Added ores_dq_lei_entities_distinct_countries_fn() and ores_dq_lei_entities_summary_by_country_fn() for GLEIF counterparty picker, deduplicating by DISTINCT ON (lei).
- PostgreSQL NOTICEs: Installed PQsetNoticeProcessor in pg_connection_guard to route PL/pgSQL messages through Boost.Log instead of stdout.
This pull request delivers crucial enhancements across three key areas: it re-establishes the full capabilities of the provisioning wizard for synthetic data generation, refines the audit logging mechanism to correctly attribute actions to service accounts, and addresses a critical startup issue affecting the ores.wt.service. These changes collectively improve the system's configurability, auditability, and operational stability.
Highlights:
- Provisioning Wizard Parity Restored: Full feature parity for the provisioning wizard was restored, reintroducing depth controls, contact counts, and a reproducibility seed for synthetic data generation after the binary-to-NATS migration.
- Performed By Audit Field Correction: The performed_by audit field was corrected to accurately reflect the service account responsible for an action, distinguishing it from the end-user captured by modified_by.
- ores.wt.service Startup Fix: A startup crash in ores.wt.service was resolved by excluding it from NATS service discovery to prevent environment variable collisions and ensuring Wt-specific arguments are correctly passed.
Notes:
- session bytes are no longer working.
projects/ores.refdata/src/repository/party_repository.cpp
const auto id_str = boost::uuids::to_string(root_id); const std::string sql = "WITH RECURSIVE party_tree AS (" " SELECT id FROM ores_refdata_parties_tbl" " WHERE id = '" + id_str + "' AND valid_to = '" + MAX_TIMESTAMP + "'" " UNION ALL"6ju " SELECT p.id FROM ores_refdata_parties_tbl p" " JOIN party_tree pt ON p.parent_party_id = pt.id" " WHERE p.valid_to = '" + MAX_TIMESTAMP + "'" ") SELECT id FROM party_tree";
Footer
| Previous: Sprint Backlog 13 |