Sprint Backlog 15
Sprint Mission
- Implement compute grid.
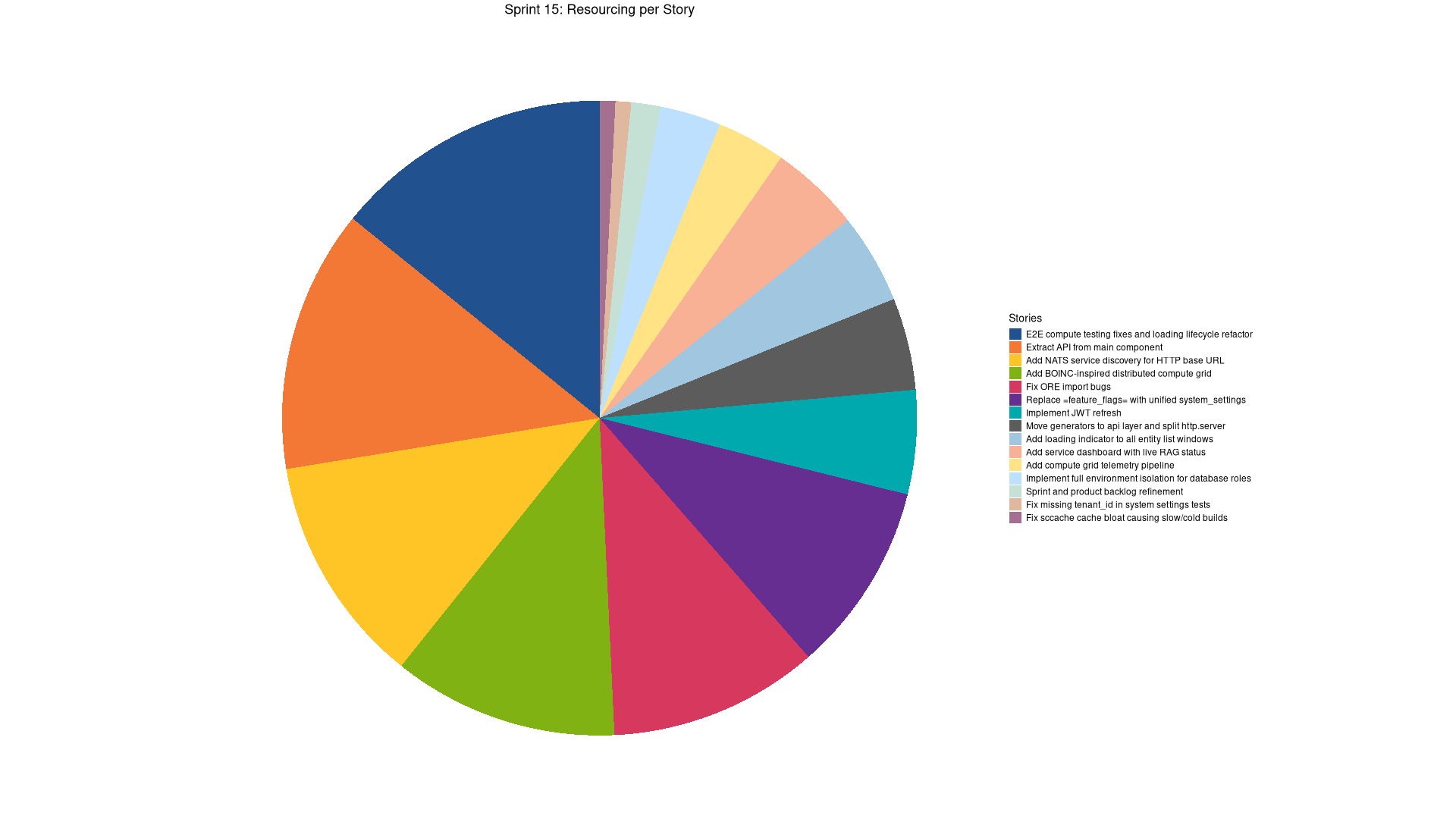
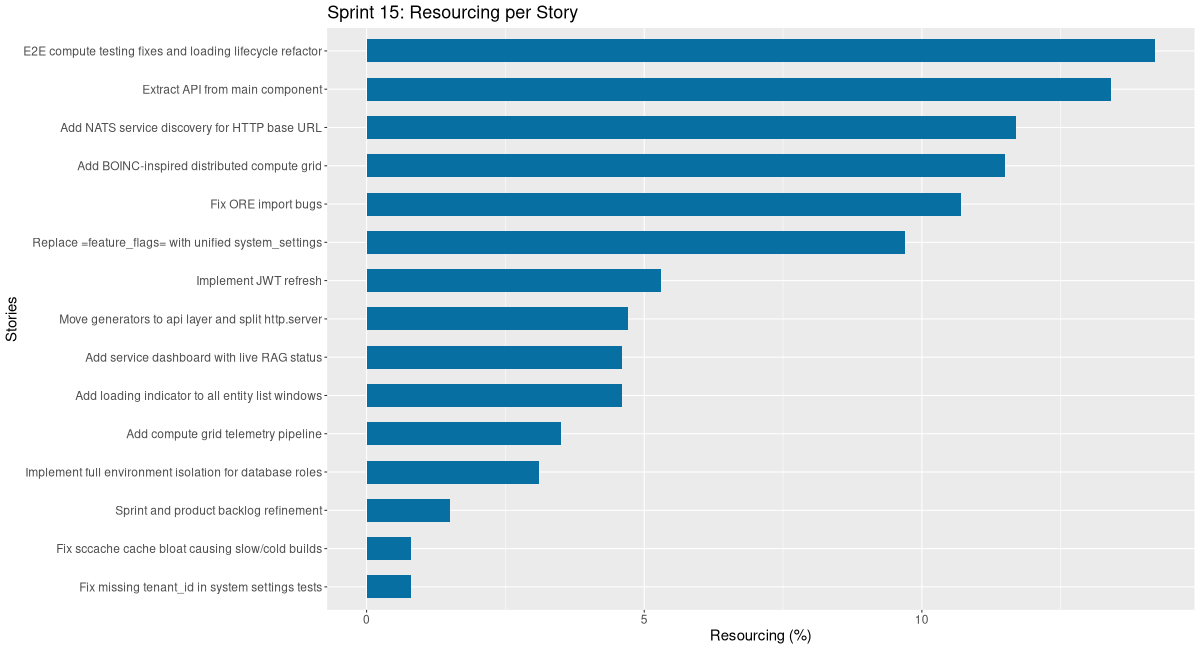
Stories
Active
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
| Total time | 3:00 | 100.0 | |||
| Stories | 3:00 | 100.0 | |||
| Active | 3:00 | 100.0 | |||
| code | CDM Phase 3: Bond instrument domain model | 3:00 | 100.0 |
| Tags | Headline | Time | % | ||
|---|---|---|---|---|---|
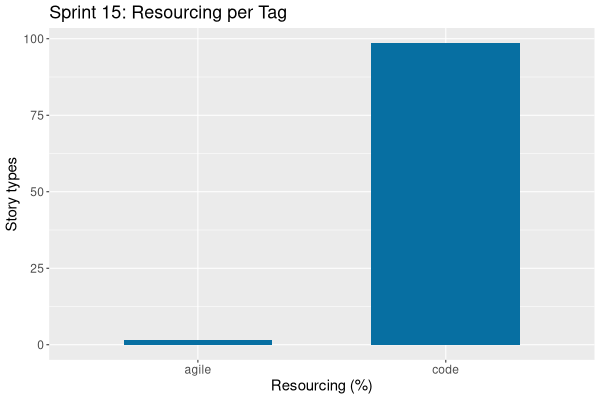
| Total time | 86:56 | 100.0 | |||
| Stories | 86:56 | 100.0 | |||
| Active | 86:56 | 100.0 | |||
| agile | Sprint and product backlog refinement | 0:54 | 1.0 | ||
| code | Add BOINC-inspired distributed compute grid | 7:03 | 8.1 | ||
| code | Fix ORE import bugs | 6:35 | 7.6 | ||
| code | Add loading indicator to all entity list windows | 2:49 | 3.2 | ||
| code | Replace feature_flags with unified system_settings |
5:59 | 6.9 | ||
| code | Implement JWT refresh | 3:16 | 3.8 | ||
| code | Add compute grid telemetry pipeline | 2:10 | 2.5 | ||
| code | Add service dashboard with live RAG status | 2:49 | 3.2 | ||
| code | E2E compute testing fixes and loading lifecycle refactor | 8:43 | 10.0 | ||
| code | Add NATS service discovery for HTTP base URL | 7:10 | 8.2 | ||
| code | Extract API from main component | 8:13 | 9.5 | ||
| code | Fix missing tenant_id in system settings tests | 0:30 | 0.6 | ||
| code | Fix sccache cache bloat causing slow/cold builds | 0:30 | 0.6 | ||
| code | Move generators to api layer and split http.server | 2:55 | 3.4 | ||
| code | Implement full environment isolation for database roles | 1:53 | 2.2 | ||
| code | Add ORES_PRESET to .env; add start-client.sh | 0:30 | 0.6 | ||
| code | End to end fixes for grid work | 4:57 | 5.7 | ||
| code | CDM Phase 1: Rates instrument domain model | 5:00 | 5.8 | ||
| code | CDM Phase 2: FX instrument domain model | 8:00 | 9.2 | ||
| code | CDM Phase 3: Bond instrument domain model | 7:00 | 8.1 |
COMPLETED Sprint and product backlog refinement agile
Updates to sprint and product backlog.
COMPLETED Add BOINC-inspired distributed compute grid code
This pull request implements a comprehensive distributed compute grid inspired by BOINC, integrating it deeply into the ORE Studio ecosystem. It introduces new domain entities, services, and executables, leveraging modern messaging and database technologies for efficient and scalable computation.
Highlights:
- Compute Grid Implementation: This PR introduces a BOINC-inspired distributed compute grid across all layers of the ORE Studio stack, including domain library, SQL schema, service executable, messaging protocol, wrapper executable, HTTP endpoints, CLI commands, and Qt list windows.
- Key Components: Key components include ores.compute domain library, ores.compute.service executable, ores.compute.wrapper executable, and integration with NATS JetStream for message handling.
- Event-Driven Architecture: The architecture is primarily event-driven, using NATS JetStream for lifecycle transitions and PostgreSQL triggers for eventing, replacing legacy PGMQ and pg_cron implementations.
- Documentation Updates: The PR updates UML diagrams and removes legacy plan documents, providing comprehensive documentation for the new compute grid.
COMPLETED Fix ORE import bugs code
This pull request significantly improves the robustness and usability of the application by addressing several critical bugs across ORE import, trading services, and the Qt UI. Key changes include enhanced data mapping for ORE currency types, better handling of trade statuses, and dynamic loading of activity types in the UI. Additionally, UI components now retain their layout, and the project version has been updated to reflect the new sprint cycle.
Highlights:
- ORE Import Bug Fixes: Resolved an Invalid monetary_nature: Crypto error by implementing a mapping for ORE CurrencyType values to appropriate database codes (e.g., Metal to commodity, Crypto to synthetic, others to fiat).
- UI Enhancements (Qt): Introduced a subject_prefix field to the AddItemDialog for environments (editable) and connections (read-only from linked environments), improving configuration clarity. Fixed an issue where ConnectionBrowserMdiWindow failed to restore its size and splitter position upon reopening.
- Trading Service Stability: Addressed an Invalid status_id: nil UUID bug by ensuring trade_status_service::resolve_status is called before every trade write operation, guaranteeing valid status IDs.
- Dynamic Activity Type Loading: Added a new trading.v1.activity_types.list NATS endpoint, allowing clients to dynamically fetch valid activity type codes from the database. This change also fixes Unknown activity type code: New import errors in the ORE Import Wizard by replacing hardcoded lifecycle events with an async database fetch.
- Sprint Management & Version Bump: Opened Sprint 15 and updated the project version to 0.0.15, reflecting ongoing development and release cycles.
COMPLETED Add loading indicator to all entity list windows code
This pull request significantly improves the user experience across all entity list windows by introducing a consistent loading indicator and centralizing the data reloading logic. By moving common loading state management to the base class, it reduces code duplication and simplifies future maintenance, ensuring that users receive clear visual feedback during data fetches.
Highlights:
- Centralized Reload Logic: Refactored the data reload lifecycle in the base EntityListMdiWindow class, centralizing common steps like clearing stale indicators and managing loading states.
- Loading Indicator Added: Introduced an indeterminate 4px progress bar (browser-style) to all entity list windows to visually indicate data loading.
- Method Renaming and Delegation: Renamed the reload() override to doReload() in all 45 subclasses of EntityListMdiWindow, with the base class now handling the reload() call and delegating to doReload().
- Explorer Window Integration: Applied the new loading indicator and reload logic to OrgExplorerMdiWindow and PortfolioExplorerMdiWindow, ensuring consistent loading feedback.
COMPLETED Replace feature_flags with unified system_settings code
Summary:
Replaces the old boolean-only `ores_variability_feature_flags_tbl` (and its `system_flags_service` typed wrapper) with a single unified `ores_variability_system_settings_tbl` that supports boolean, integer, string, and JSON value types. All code across the stack — database, service, messaging, CLI, shell, HTTP, Qt UI — has been migrated to the new type. All legacy `feature_flags` and `system_flags` files and names have been removed.
Changes:
- Phase 1–5 (variability): New `ores_variability_system_settings_tbl` SQL schema, domain type, JSON/table I/O, entity/mapper/repository, service with typed accessors (`get_bool`, `get_int`, `get_string`, `get_json`), NATS handler/protocol (`variability.v1.settings.*`), eventing (`system_setting_changed_event`)
- Phase 6 (shell): Migrated `variability_commands` from `list-flags`/`add-flag` to `list-settings`/`save-setting`
- Phase 7 (CLI): New `add_system_setting_options`, `system_settings_parser`; updated `entity` enum, `add_options` variant, application dispatch
- Phase 8 (cross-module): Updated `iam_routes`, `iam` auth handler, `variability_routes`, `http.server` application, `wt.service` application context, Qt currency windows, `TenantProvisioningWizard`, event viewer
- Phase 9 (deletion): Removed all legacy files — 29 `feature_flags`/`system_flags` source files, 5 test files, 4 CLI files; updated `registrar.cpp` and `variability_routes` to use new protocol/endpoint
- Rename pass: 14 Qt files renamed (`FeatureFlag*` → `SystemSetting*`); all string literals, log messages, SQL function names, ORG docs, JSON codegen models updated throughout
COMPLETED Implement JWT refresh code
Problem:
2026-03-20 10:04:27.471965 [DEBUG] [ores.trading.messaging.trade_handler] Completed ores.dev.local1.trading.v1.trades.list 2026-03-20 10:05:17.241863 [DEBUG] [ores.trading.messaging.trade_handler] Handling ores.dev.local1.trading.v1.trades.list 2026-03-20 10:05:17.241962 [TRACE] [ores.security.jwt.jwt_authenticator] Validating JWT token 2026-03-20 10:05:17.242485 [WARN] [ores.security.jwt.jwt_authenticator] JWT verification failed: token expired 2026-03-20 10:05:17.242569 [DEBUG] [ores.trading.service.trade_service] Listing trades with offset=0, limit=100
Add JWT auth telemetry hypertable:
This pull request significantly enhances the authentication system by introducing comprehensive telemetry for JWT-based authentication events and improving client-side session management. It establishes a TimescaleDB hypertable to meticulously log all authentication-related activities, providing valuable data for monitoring and analysis. Concurrently, the client application now proactively refreshes JWTs and gracefully handles session expirations, leading to a more resilient and user-friendly authentication experience.
Highlights:
- Authentication Telemetry Database: Introduced ores_iam_auth_events_tbl TimescaleDB hypertable to record various authentication events, including login success/failure, logout, token refresh, max session exceeded, and signup success/failure.
- Aggregated Views and Retention Policies: Created hourly and daily continuous aggregate views (ores_iam_auth_events_hourly_vw, ores_iam_auth_events_daily_vw) with retention policies set to 90 days for raw events and hourly views, and 3 years for daily views.
- Robust Event Recording: Ensured the auth_event_repository is insert-only and that telemetry failures do not interrupt the core authentication response flow by wrapping calls in try/catch blocks.
- Proactive JWT Refresh (Client-side): Implemented a QTimer in ClientManager to proactively refresh JWTs before they expire, improving user experience by preventing unexpected logouts.
- Automatic JWT Refresh (Server-side): Modified nats_session to automatically attempt JWT refresh when a token_expired error is received from the server, transparently handling token renewal.
- Session Expiry Handling: Added client-side logic in ClientManager and MainWindow to detect and notify users when a session has reached its maximum allowed duration (max_session_exceeded), prompting re-login.
- Error Reply Refactoring: Updated various *handler.hpp files in ores.compute to use error_reply for handling failed request context creation, standardizing error responses.
JWT token refresh: configurable lifetimes, refresh subject, token_expired propagation:
This pull request significantly refines the Identity and Access Management (IAM) system by introducing flexible JWT token management and robust error handling. It allows administrators to configure token lifetimes, implements a secure token refresh mechanism, and ensures that authentication-related errors are explicitly communicated to clients rather than silently failing. These changes improve the system's security, configurability, and overall reliability for token-based authentication.
Highlights:
- Configurable JWT Token Lifetimes: Introduced new system settings (iam.token.access_lifetime_seconds, iam.token.party_selection_lifetime_seconds, iam.token.max_session_seconds, iam.token.refresh_threshold_pct) to allow dynamic configuration of JWT access token, party selection token, and maximum session durations. Hardcoded values are replaced with these configurable settings.
- JWT Token Refresh Mechanism: Implemented a new token refresh endpoint (iam.v1.auth.refresh) and a validate_allow_expired() method in the JWT authenticator. This allows clients to obtain new access tokens using an expired but otherwise valid token, subject to a maximum session ceiling.
- Enhanced Error Propagation: Fixed a silent fallback bug in make_request_context(), which now explicitly returns error_code::token_expired for expired tokens and error_code::unauthorized for invalid/missing tokens. An error_reply() helper was added to send these errors via X-Error NATS headers.
- Widespread Error Handling Update: Updated all 48 domain handler files across various services to correctly handle and propagate the new std::expected return type from make_request_context(), ensuring consistent client-side error feedback.
- Hot-Reloading of Token Settings: Enabled account_handler and auth_handler to hot-reload token settings dynamically upon receiving ores.variability.system_setting_changed events, eliminating the need for service restarts when these settings are updated.
JWT refresh: shell reactive retry and Qt proactive timer (Phases 4-5):
This pull request implements JWT token refresh functionality in both the shell and Qt clients. It introduces reactive retries in the shell upon token expiration and proactive refresh timers in the Qt client to prevent session expiry. The changes ensure a smoother user experience by automatically refreshing tokens and prompting re-login only when necessary.
Highlights:
- JWT Refresh - Shell: The nats_session::authenticated_request() function now validates the X-Error header in each reply. If a token_expired error is detected, it triggers a refresh, retrieves an updated JWT, and retries the original request once. A max_session_exceeded error will throw an exception, prompting the user to re-login.
- JWT Refresh - Qt: The ClientManager now uses a QTimer that activates after each successful login and party selection. The timer fires at 80% of the token lifetime, triggering an iam.v1.auth.refresh call. A sessionExpired() signal is emitted if the refresh fails due to session expiry, which MainWindow connects to, displaying a warning dialog and reopening the login dialog.
- Completion of JWT Refresh Plan: This pull request finalizes the JWT token refresh plan, incorporating all five phases: system settings registration, configurable lifetimes, token_expired error propagation, shell reactive retry, and Qt proactive timer with session-expired dialog.
COMPLETED Add compute grid telemetry pipeline code
This pull request significantly enhances the compute grid's observability by implementing a dedicated telemetry pipeline. It transitions the dashboard's data sourcing from direct, ad-hoc database queries to a centralized, time-series-based system using TimescaleDB. This change improves performance, scalability, and consistency of monitoring data by introducing distinct server-side and node-side samplers that collect and persist metrics, and a unified NATS endpoint for dashboard consumption.
Highlights:
- Compute Grid Telemetry System: Introduced a comprehensive telemetry system for the compute grid, moving dashboard statistics from ad-hoc live queries to a robust TimescaleDB time-series storage.
- New TimescaleDB Hypertables: Added two new TimescaleDB hypertables, ores_compute_grid_samples_tbl for server-side metrics and ores_compute_node_samples_tbl for per-node execution statistics, both with 30-day retention policies.
- Server-Side Poller (compute_grid_poller): Implemented a new compute_grid_poller in ores.compute.service that runs as an async Boost.ASIO coroutine, sampling and storing grid-wide metrics every 30 seconds.
- Node-Side Reporter (node_stats_reporter): Developed a node_stats_reporter in ores.compute.wrapper to accumulate per-task timing and byte-transfer metrics, publishing node_sample_message to NATS every 30 seconds for persistence by the compute service.
- NATS Request/Reply for Dashboard: Created a get_grid_stats NATS request/reply handler to serve the latest telemetry snapshot to the dashboard, replacing multiple ad-hoc NATS queries with a single, efficient call.
- Dashboard Integration: Updated the ComputeDashboardMdiWindow in the Qt client to consume data from the new get_grid_stats endpoint, populating all six statistical boxes from the unified response.
COMPLETED Add service dashboard with live RAG status code
This pull request introduces a service health monitoring system that provides real-time insights into the status of all running services. It includes a new TimescaleDB hypertable for storing service heartbeats, a reusable heartbeat publisher coroutine, and a Qt UI dashboard for visualizing service health using RAG status indicators. This enhancement improves operational visibility and enables proactive issue detection.
Highlights:
- Service Health Monitoring: Introduces a comprehensive service health monitoring system using heartbeats and a RAG status dashboard.
- New TimescaleDB Hypertable: Adds a new TimescaleDB hypertable for persistent storage of service heartbeat samples.
- Heartbeat Publisher: Implements a reusable header-only coroutine for publishing service heartbeats via NATS.
- Qt UI Dashboard: Creates a new Qt UI dashboard to display service status with RAG indicators.
- Service Integration: Integrates heartbeat publishing into all domain services to ensure complete visibility.
COMPLETED E2E compute testing fixes and loading lifecycle refactor code
This pull request significantly enhances the robustness and usability of the compute grid and related data management features. It introduces a standardized loading lifecycle for client-side models, streamlines change reason handling across various detail dialogs, and improves data integrity by fixing UUID generation and refining platform management for application versions. These changes collectively contribute to a more stable and user-friendly application, particularly for end-to-end testing and data entry workflows.
Highlights:
- Change Reason Symmetry: Introduced applies_to_new to the change reason domain type and SQL schema, ensuring that 'new record' operations can also be associated with specific, data-driven change reasons. This centralizes change reason prompting into a single helper method in DetailDialogBase for all operation types (create, amend, delete), eliminating duplication across detail dialogs.
- Compute RLS Policies: Fixed Row-Level Security (RLS) policies for compute applications and app versions, making them visible to all tenants as system-owned global registries.
- UUID Generation: Replaced hardcoded c0ffee00 UUIDs in the ORE app seed script with gen_random_uuid() and name-based idempotency, improving data integrity and consistency.
- ReflectCPP Compatibility: Removed a .response<list_settings_response>() call in variability routes that was causing a Clang consteval char/signed char deduction bug in reflectcpp.
- Loading Lifecycle Refactor: Addressed missing endLoading() calls in all six compute grid MdiWindows, which previously caused the reload button to be permanently disabled after the first load. This was achieved by introducing an AbstractClientModel base class with standard dataLoaded() and loadError() signals, and wiring these signals to endLoading() automatically via EntityListMdiWindow::connectModel().
- App Version Platform Management: Refactored app_version to support multiple platforms via a new junction table (ores_compute_app_version_platforms_tbl), replacing the previous single-string platform field. This includes updates to the domain, repository, CLI, and Qt UI to manage platform selections using a multi-select widget.
- Improved UI for App and Workunit Selection: Enhanced AppVersionDetailDialog with a QComboBox for selecting parent applications and WorkunitDetailDialog with QComboBoxes for selecting batches and app versions, replacing plain UUID text boxes for better user experience.
COMPLETED Add NATS service discovery for HTTP base URL code
This pull request introduces NATS service discovery for the HTTP base URL, refactors code for better dependency management, and includes an architecture migration plan. The changes aim to improve the client's ability to automatically configure itself and lay the groundwork for a cleaner service architecture.
Highlights:
- NATS Service Discovery: Qt client now automatically discovers the HTTP server's base URL after login, eliminating manual http_port configuration.
- Code Reorganization: Protocol types are moved to ores.http (shared utility lib) so ores.qt can include them without linking ores.http.server.
- Architecture Migration Plan: An architecture migration plan is added for splitting service libraries into *.types (shared contract) and *.core (implementation) components.
COMPLETED Extract API from main component code
Extract ores.iam.api and ores.compute.api:
This pull request implements the first phase of a significant architecture migration, separating the API contracts from the core logic for the Identity and Access Management (IAM) and Compute domains. This refactoring enhances the system's modularity by clearly defining interfaces and reducing tight coupling between components. Consumers now interact with dedicated API layers for data structures and messaging, while business logic and persistence are encapsulated within the core modules. This change paves the way for a more maintainable and scalable codebase.
Highlights:
- Architectural Refactoring: The ores.iam and ores.compute modules have been refactored into distinct API and core components to improve modularity and dependency management.
- New API Modules: Introduced ores.iam.api and ores.compute.api as shared contract layers, containing domain POCOs, IO helpers, eventing types, and protocol/messaging headers.
- Core Module Renaming: Existing ores.iam and ores.compute modules were renamed to ores.iam.core and ores.compute.core respectively, now housing handlers, service logic, repositories, and registrars.
- Dependency Updates: All consuming modules, including ores.qt, ores.cli, ores.shell, ores.http.server, ores.wt.service, ores.synthetic, ores.eventing/tests, ores.dq, ores.iam.service, ores.compute.service, and ores.compute.wrapper, have been updated to link against the correct new API or core layers.
- Test Configuration Fixes: Corrected CMakeLists files in the new API components to properly link ores.testing.lib.
Split ores.refdata into ores.refdata.api and ores.refdata.core:
This pull request significantly improves the modularity and separation of concerns within the ores.refdata component by splitting it into an API-focused module and a core implementation module. This architectural change enhances maintainability, reduces coupling, and clarifies dependencies across the codebase. Additionally, it includes a quality-of-life improvement for local development by automating the loading of test database credentials.
Highlights:
- Refdata Module Split: The ores.refdata component has been refactored into two distinct modules: ores.refdata.api for public contracts (domain types, eventing, messaging, CSV support) and ores.refdata.core for internal logic (handlers, repositories, generators, services).
- Consumer Updates: All dependent modules (ores.cli, ores.qt, ores.ore, ores.http.server, ores.wt.service, ores.iam.core, ores.eventing) have been updated to correctly reference the new ores.refdata.api module for their public contract needs or ores.refdata.core for internal logic.
- Local Development Setup: Added functionality to load ORES_TEST_DB_* credentials from the .env file during CMake configuration, streamlining local development testing.
Split ores.scheduler, ores.assets, ores.variability and ores.synthetic into api and core layers:
This pull request implements a significant architectural refactoring by splitting several key modules into separate API and core layers. This change enhances modularity, clarifies dependencies, and aligns the codebase with a standardized three-layer service pattern. The API layers now exclusively define interfaces and data structures, while the core layers encapsulate the business logic and implementation details. This separation improves maintainability and prepares the system for future development and scaling.
Highlights:
- Architectural Split: The ores.scheduler, ores.assets, ores.variability, ores.synthetic, ores.trading, and ores.reporting modules have been refactored into distinct *.api and *.core layers. The *.api layers now contain domain types, eventing, and messaging protocol headers, while the *.core layers retain handlers, repositories, generators, and service logic.
- New API Modules: New ores.assets.api, ores.reporting.api, and ores.scheduler.api modules were added, including their respective source, test, and modeling CMake configurations. This establishes clear boundaries for API definitions.
- Module Renaming: Existing ores.assets, ores.reporting, and ores.scheduler modules were renamed to ores.assets.core, ores.reporting.core, and ores.scheduler.core respectively, to house their core implementation logic.
- Dependency Updates: Numerous files across the codebase, including CMakeLists.txt files and C++ source/header files, were updated to reflect the new *.api and *.core naming conventions and adjust include paths and library linkages accordingly.
- Migration Progress: This change completes Phase 2 of the service architecture migration, ensuring all ten service libraries now adhere to the three-layer api/core/service pattern.
COMPLETED Fix missing tenant_id in system settings tests code
This pull request addresses a critical issue in the system settings repository tests where the tenant_id was not being properly set when creating system setting objects. By modifying the test helper function and its invocations, the tests now correctly provide a tenant_id, preventing database errors and ensuring the reliability of repository operations related to system settings.
Highlights:
- Test Function Signature Update: The make_system_setting() function in repository_system_settings_repository_tests.cpp was updated to include tenant_id as a required parameter.
- Tenant ID Assignment: The tenant_id is now correctly assigned within the make_system_setting() function, addressing a previous omission.
- Call Site Corrections: All seven call sites of make_system_setting() across the test file have been modified to pass the h.tenant_id().to_string() value, ensuring proper tenant_id population.
- PostgreSQL Error Resolution: This change resolves an issue where PostgreSQL rejected INSERT statements due to an 'invalid input syntax for type uuid: ""' error, caused by the missing tenant_id.
COMPLETED Fix sccache cache bloat causing slow/cold builds code
CI builds were taking 2+ hours even for trivial single-file changes. Investigation revealed the GitHub Actions cache was at 11.5 GB — over the 10 GB repo limit, causing LRU evictions of sccache entries and forcing cold full rebuilds.
Root causes
Cause Detail Per-PR sccache saves Every PR saved its own ~1 GB sccache entry. 12 entries across concurrent PRs = 8.5 GB of sccache alone sccache too small 1000M limit caused within-build LRU eviction for 1,362 source files; next build starts with a partial cache No cross-PR cache sharing GitHub cache scoping means each PR can only read from its own scope or main, so Qt (6 × ~450 MB = 2.7 GB) and sccache were duplicated per PR Evidence
Step timings from a recent failed canary run (run 23465294275):
- All pre-build steps (Qt, vcpkg, sccache restore): ~2 minutes
- Run CTest workflow: 7,149 seconds (119 minutes)
- Post sccache save: 7s — saved successfully, then evicted by next concurrent PR
- The Cache CMake build output step added in some PR branches always completes in 1s (cache miss — the debug build output is 8.3 GB locally, far beyond GitHub's per-entry limits).
COMPLETED Move generators to api layer and split http.server code
This pull request implements a significant architectural refactoring by relocating synthetic data generators from core to API layers across multiple components and streamlining the ores.http.server module. The changes enhance modularity and reduce tight coupling by moving domain-specific HTTP route handlers and an in-memory authentication service to their appropriate domain core or API layers. This effort aligns the codebase with a previously documented architectural plan, improving maintainability and clarity of component responsibilities.
Highlights:
- Generator Migration: Moved synthetic generators from core to api layers across ores.trading, ores.reporting, ores.iam, ores.refdata, and ores.compute components, along with their associated tests.
- Dependency Refinement: Corrected stale link dependencies in ores.dq.core and ores.ore to point to the appropriate api libraries, improving architectural clarity.
- Service Relocation: Relocated the auth_session_service from ores.iam.core to ores.iam.api, as it has no core dependencies and is in-memory only.
- HTTP Server Split: Restructured ores.http.server by moving domain-specific HTTP route handlers (iam, refdata, variability, assets) into their respective domain core modules, updating namespaces and dependencies.
- HTTP Server Simplification: Ensured ores.http.server now exclusively manages generic server infrastructure, with compute_routes being the only remaining domain-specific route.
- Directory Standardization: Standardized generator directory naming from generator/ (singular) to generators/ (plural) within the ores.trading component.
- New Dependency: Added faker-cxx::faker-cxx as a private dependency to the CMakeLists of affected api libraries to support generator functionality.
COMPLETED Implement full environment isolation for database roles code
This pull request significantly enhances the system's robustness and maintainability by introducing full environment isolation for PostgreSQL database roles and users. This change prevents cross-environment contamination during development and testing. Alongside this, the PR includes substantial architectural refactoring, moving data generators and core HTTP components to more appropriate API layers, and relocating a key authentication service. These structural improvements streamline development workflows and ensure more reliable testing across different environments.
Highlights:
- Full Database Environment Isolation: Implemented environment-prefixed PostgreSQL roles and users, ensuring that database operations for one environment (e.g., local1) do not interfere with others (e.g., local2).
- PostgreSQL Scripting Enhancements: Resolved issues with psql variable substitution within DO blocks by utilizing set_config and current_setting for robust scripting.
- Improved Test Environment Setup: Introduced ORES_TEST_ENV_CMD to correctly pass environment variables to custom test runners (make rat), ensuring consistent test execution.
- Architectural Refactoring of Generators: Relocated various data generators from core to api layers across multiple services (IAM, Refdata, Trading, Reporting, Compute), promoting better modularity and dependency management.
- HTTP Core Extraction: Created a new ores.http.core module to house domain-layer HTTP route handlers, separating concerns from the ores.http.api module.
- Service Relocation: Moved the auth_session_service from iam.core to iam.api to resolve cyclic dependencies and improve the IAM module's structure.
- Test Fixes: Addressed variability core tests that were failing due to missing system tenant UUIDs.
COMPLETED Add ORES_PRESET to .env; add start-client.sh code
This pull request significantly refines the development environment setup by centralizing the build preset configuration within the .env file, ensuring consistency across various operational scripts. It also introduces a new, flexible script for launching the Qt client, enhancing the developer experience with customizable instance colors and names. These changes collectively improve the robustness and usability of the build and runtime environment for ORE Studio.
Highlights:
- Centralized Preset Configuration: The init-environment.sh script now requires a –preset argument, which is then stored as ORES_PRESET in the .env file, establishing a single source of truth for the build preset across all tools.
- Service Script Enhancements: The start-services.sh, stop-services.sh, and status-services.sh scripts have been updated to source the ORES_PRESET from the .env file by default, with an option to override it via a command-line argument for ad-hoc use, removing hardcoded defaults.
- New Qt Client Launch Script: A new start-client.sh script has been added to launch the ORE Studio Qt client, offering options for specifying the build preset, custom instance colors (named or hex), and display names, enabling multiple colored instances to run simultaneously.
- Emacs Lisp Integration: The ores-prodigy.el Emacs Lisp file now automatically registers services based on the ORES_PRESET value loaded from the .env file, streamlining the setup process for Emacs users.
COMPLETED End to end fixes for grid work code
This pull request delivers a comprehensive set of fixes and enhancements across the compute grid system, addressing critical end-to-end issues. The changes improve the reliability of service status reporting, ensure accurate result processing and data persistence, and refine the user interface for a more intuitive experience. Key areas of improvement include data flow integrity, authentication handling for internal services, and robust error management within the compute infrastructure.
Highlights:
- Service Dashboard Improvements: Fixed services showing 'Red' on shutdown by raising the offline threshold to 120 seconds. Corrected version display from '1.0' to the actual version using the ORES_VERSION macro. Enhanced status-services.sh to distinguish between node and service counts.
- Compute Host Heartbeat and Timestamp Fixes: Addressed the 'Online hosts always 0' issue by implementing an idle heartbeat sender in the wrapper. Resolved a silent timestamp bug where std::format produced nanoseconds that sqlgen::Timestamp couldn't parse, causing last_rpc_time to be NULL. Migrated timestamp conversion to ores.platform::datetime for cross-platform compatibility.
- Result Processing and Authentication: Fixed results getting stuck 'InProgress' by allowing result_handler::submit to use the service context directly, as the wrapper sends unauthenticated requests.
- Outcome Code Correction: Corrected the mapping of outcome codes, changing wrapper's internal 0/1 codes to the domain's 1=Success, 3=ClientError.
- Host ID Persistence: Resolved 'host_id all-zeros' by adding host_id to submit_result_request, ensuring the wrapper sends its host ID on submission, and the handler persists it to the result record.
- File Extension Preservation in URIs: Ensured original file extensions (.tar.gz, .csv, .xml) are preserved in package and workunit artifact URIs. Generalized HTTP compute routes from fixed /input and /config segments to a flexible /{artifact} parameter.
- UI Bug Fixes: Fixed a double-slash URL bug in AppVersionDetailDialog during re-upload URL construction. Resolved a SIGSEGV issue caused by a dangling window pointer in onWindowMenuAboutToShow.
- Result UI Enhancements: Improved the Result UI by rendering 'State' and 'Outcome' columns as colored pill badges (matching accounts table style) via ClientResultItemDelegate. Mapped labels to human-readable strings (e.g., Done, Running, Failed).
- Main Window Geometry Persistence: Implemented saving and restoring the main window's geometry across sessions.
- Compute Wrapper Robustness: Enhanced the compute wrapper with RAII thread cleanup and a terminate() guard on startup exceptions.
COMPLETED Move badges to database code
At present we did some hackery to use badges on Qt UI. ideally we want the database to have some meta-data about badges and then use that to drive the UI so we can reuse it for Wt. See design.
Phase 1 — Infrastructure
- Tasks
[ ]Create codegen model:badge_severity_domain_entity.json[ ]Create codegen model:code_domain_domain_entity.json[ ]Create codegen model:badge_definition_domain_entity.json[ ]Create codegen model:badge_mapping_junction.json[ ]Run codegen and integrate generated SQL artefacts[ ]Run codegen and integrate generated C++ artefacts[ ]Create population seed data from hardcoded colours[ ]ImplementBadgeCacheinores.qt[ ]WireBadgeCacheinto client startup sequence
COMPLETED CDM Phase 1: Rates instrument domain model code
Implement the rates instrument domain model (Phase 1 of the CDM-inspired instrument design). See plan for architecture.
Covers Swap, CrossCurrencySwap, CapFloor, and Swaption, backed by two new
temporal tables: ores_trading_instruments_tbl and
ores_trading_swap_legs_tbl.
- Tasks
[X]SQL:ores_trading_instruments_tbl+ notify trigger + drop files[X]SQL:ores_trading_swap_legs_tbl+ notify trigger + drop files[X]SQL: Register intrading_create.sql,drop_trading.sql,populate_trading.sql+ seed data[X]Domain:instrumentstruct, JSON I/O, table I/O, generator, protocol[X]Domain:swap_legstruct, JSON I/O, table I/O, generator, protocol[X]Repository:instrumententity, mapper, repository, service[X]Repository:swap_legentity, mapper, repository, service[X]Server: messaging handler + registrar registration[X]Qt UI:ClientInstrumentModel,InstrumentMdiWindow,InstrumentDetailDialog,InstrumentHistoryDialog,InstrumentController,MainWindowintegration[ ]CLI:instruments list,instruments add,instruments delete(deferred to follow-up)
- Notes
Story is BLOCKED pending PR review. All implementation is complete except CLI commands which are deferred to a follow-up story. Builds cleanly.
Pull Request: OreStudio/OreStudio#569
COMPLETED CDM Phase 2: FX instrument domain model code
Implement the FX instrument domain model (Phase 2 of the CDM-inspired instrument design). See plan for architecture.
Covers FxForward, FxSwap, and FxOption, backed by one new temporal table:
ores_trading_fx_instruments_tbl (bought/sold currencies and amounts,
value_date, settlement, and option fields for FxOption).
- Tasks
[X]SQL:ores_trading_fx_instruments_tbl+ notify trigger + drop files[X]SQL: Register intrading_create.sql,drop_trading.sql[X]Domain:fx_instrumentstruct, JSON I/O, table I/O, generator, protocol[X]Repository:fx_instrumententity, mapper, repository[X]Service:fx_instrument_service[X]Server: messaging handler + registrar registration[X]Qt UI:ClientFxInstrumentModel,FxInstrumentMdiWindow,FxInstrumentDetailDialog,FxInstrumentHistoryDialog,FxInstrumentController,MainWindowintegration[ ]Database: recreate to pick up new table
COMPLETED CDM Phase 4: Credit instrument domain model code
Implement the credit instrument domain model (Phase 4 of the CDM-inspired instrument design). See plan for architecture.
Covers CreditDefaultSwap, CDSIndex, and SyntheticCDO, backed by one new
temporal table: ores_trading_credit_instruments_tbl (reference_entity,
currency, notional, spread, recovery_rate, tenor, start_date, maturity_date,
day_count_code, payment_frequency_code, and optional fields for index_name,
index_series, seniority, restructuring, description).
- Tasks
[X]SQL:ores_trading_credit_instruments_tbl+ notify trigger + drop files[X]SQL: Register intrading_create.sql,drop_trading.sql[X]Domain:credit_instrumentstruct, JSON I/O, table I/O, protocol messages[X]Repository:credit_instrumententity, mapper, repository[X]Service:credit_instrument_service[X]Server: messaging handler + registrar registration[X]Qt UI:ClientCreditInstrumentModel,CreditInstrumentMdiWindow,CreditInstrumentDetailDialog,CreditInstrumentHistoryDialog,CreditInstrumentController,MainWindowintegration[ ]Database: recreate to pick up new table
COMPLETED CDM Phase 3: Bond instrument domain model code
Implement the bond instrument domain model (Phase 3 of the CDM-inspired instrument design). See plan for architecture.
Covers Bond, ForwardBond, CallableBond, ConvertibleBond, and BondRepo, backed
by one new temporal table: ores_trading_bond_instruments_tbl (issuer,
currency, face_value, coupon_rate, coupon_frequency_code, day_count_code,
issue_date, maturity_date, and optional fields for settlement_days, call_date,
conversion_ratio, description).
- Tasks
[X]SQL:ores_trading_bond_instruments_tbl+ notify trigger + drop files[X]SQL: Register intrading_create.sql,drop_trading.sql[X]Domain:bond_instrumentstruct, JSON I/O, table I/O, protocol messages[X]Repository:bond_instrumententity, mapper, repository[X]Service:bond_instrument_service[X]Server: messaging handler + registrar registration[X]Qt UI:ClientBondInstrumentModel,BondInstrumentMdiWindow,BondInstrumentDetailDialog,BondInstrumentHistoryDialog,BondInstrumentController,MainWindowintegration[ ]Database: recreate to pick up new table
AI Generated Sprint Summary
# **ORE Studio Sprint 15 – Release Notes** *March 2026* Sprint 15 delivered the BOINC-inspired distributed compute grid, a full service architecture migration to `*.api`/`*.core` layers, a production-grade JWT refresh system, and four new CDM instrument domain models. --- ## ✅ **Highlights** - **Distributed compute grid** — full stack implementation (domain, SQL, service, wrapper, NATS JetStream, Qt UI) inspired by BOINC, with telemetry pipeline and RAG service health dashboard. - **Service architecture migration** — all ten service libraries (`iam`, `refdata`, `compute`, `scheduler`, `assets`, `variability`, `synthetic`, `trading`, `reporting`, `http.server`) split into `*.api` (contracts) and `*.core` (implementation) layers. - **JWT token refresh** — configurable lifetimes via system settings, `iam.v1.auth.refresh` endpoint, reactive shell retry, proactive Qt timer, and `ores_iam_auth_events_tbl` TimescaleDB telemetry hypertable. - **CDM instrument models** — Rates (Swap, CrossCurrencySwap, CapFloor, Swaption), FX (FxForward, FxSwap, FxOption), Bond (Bond, ForwardBond, CallableBond, ConvertibleBond, BondRepo), and Credit (CDS, CDSIndex, SyntheticCDO). - **Unified system settings** — replaced `ores_variability_feature_flags_tbl` with `ores_variability_system_settings_tbl` supporting bool, int, string, and JSON value types across all stack layers. --- ## 🛠️ **Key Improvements** ### **Compute Grid** - BOINC-inspired grid with `ores.compute.service` and `ores.compute.wrapper` executables; NATS JetStream lifecycle transitions replace legacy PGMQ/pg_cron. - Telemetry: `ores_compute_grid_samples_tbl` and `ores_compute_node_samples_tbl` hypertables; `get_grid_stats` unified NATS endpoint for dashboard. - E2E fixes: result-stuck-InProgress bug, host_id persistence, outcome code mapping, SIGSEGV on window close, file extension preservation in artifact URIs. - Loading lifecycle refactored via `AbstractClientModel` with `dataLoaded()`/`loadError()` signals wired to `endLoading()` across all six compute MdiWindows. ### **Authentication & Security** - Token lifetimes configurable via `iam.token.*` system settings; hot-reloaded on `system_setting_changed` events. - `make_request_context()` now explicitly returns `token_expired` / `unauthorized` error codes via `X-Error` NATS headers — updated across all 48 domain handlers. - Auth telemetry records login, logout, refresh, max-session events with 90-day/3-year retention policies. ### **Architecture** - All modules migrated to `*.api` / `*.core` three-layer pattern; HTTP route handlers relocated to domain core modules. - NATS service discovery: Qt client auto-discovers HTTP base URL after login via `ores.http` shared protocol types — eliminates manual `http_port` config. - Full PostgreSQL environment isolation: environment-prefixed roles prevent cross-environment contamination. ### **Infrastructure & DX** - `sccache` CI bloat fixed: cross-PR cache sharing, increased sccache limit — reduced cold build times from 2+ hours. - `ORES_PRESET` stored in `.env`; new `start-client.sh` supports multi-instance coloured Qt clients. - Loading indicators (4px indeterminate progress bar) added to all 45+ entity list windows. - Badge system Phase 1 infrastructure: `badge_definition` and `badge_mapping` domain entities with DB-driven metadata for reuse across Qt and Wt. --- ## ⚠️ **Known Issues & Postponed** - **CDM CLI commands** (instruments list/add/delete) deferred to a follow-up story for all four instrument phases. - **Database recreate** required to pick up new `ores_trading_fx_instruments_tbl`, `ores_trading_bond_instruments_tbl`, `ores_trading_credit_instruments_tbl` tables. - **Three-level provisioning** (party wizard split, `provision-parties` endpoint, `ores.workflow` orchestration service) — Phase 1 landed late in sprint; Phases 2–3 deferred to Sprint 16. --- ## 📊 **Time Summary** - **Total effort**: 86h 56m - **Code**: 99% | **Agile/Analysis/Doc**: 1% - Top tasks: E2E compute fixes (8h 43m), API extraction (8h 13m), CDM FX (8h 00m), CDM Bond (7h 00m), NATS service discovery (7h 10m), BOINC compute grid (7h 03m) --- *Next sprint: Complete the three-level provisioning workflow service (`ores.workflow`), advance CDM to equity/commodity phases, and begin RBAC handler guards.* ---
Footer
| Previous: Sprint Backlog 14 | Next: TBD |