Sprint 10
Table of Contents
This page documents a sprint (Sprint 10) of ORE Studio v0. It captures the sprint's mission, current status, and the stories that compose it. For the surrounding context — version goals, sprint order, and product identity — see Version 0.
Mission
Originally data quality and code generation work. Delivered exactly
that: a simple in-tree codegen that emits domain-types SQL and the ER
diagram; xsdcpp-based codegen for ORE XML inside a dedicated
ores.ore component; the 13 reference-data types party needs landed
through FpML codegen; a metadata/production schema split that resolves
the bootstrap paradox; dataset bundles and a Qt System Provisioner
Wizard that uses them.
Status
| Field | Value |
|---|---|
| State | DONE |
| Parent version | Version 0 |
| Previous | Sprint 09 |
| Start | 2026-01-20 |
| End (expected) | 2026-01-28 |
| Now | Sprint closed 2026-01-27. Two stories carry forward: the FPML export/import implementation and the BOINC compute-grid design. |
| Waiting on | None — carried items scheduled forward. |
| Next | Sprint 11 |
| Release Notes | Release notes |
| Last touched | 2026-01-27 |
Achievements
- ORE XML codegen established (ores.ore + xsdcpp; MSVC-compatible).
- 13 FPML party-scheme types generated via the new party codegen path.
- Dataset bundles and System Provisioner Wizard landed.
- In-tree codegen infrastructure with domain-types SQL and ER diagram generation.
- SQL directory reorganised into create/, drop/, populate/ per component.
- Metadata/production schema split established.
Stories
For the definitions of the themes see Themes.
Infrastructure
| Story | State | Start | End | Description |
|---|---|---|---|---|
| Schema polish | DONE | 2026-01-26 | layer cleanup, rounding types, icon labels, mapping artefact. |
Product
| Story | State | Start | End | Description |
|---|---|---|---|---|
| Party schemes and FPML reference data | DONE | 2026-01-23 | 13 types via FpML codegen + DQ artefact workflow; GLEIF subset. Continues from sprint 09 party-database groundwork. | |
| Image cache polish | DONE | 2026-01-23 | reload on new datasets; incremental loading via modified_since. |
|
| ORE XML codegen | DONE | 2026-01-27 | ores.ore + xsdcpp + Windows MSVC fix. |
|
| Dataset bundles and provisioning | DONE | 2026-01-27 | metadata/production schema split, bundles, System Provisioner Wizard. | |
| Librarian polish | DONE | 2026-01-27 | sprint-09 PR-review fix-up. | |
| FPML export and import groundwork | BACKLOG | ores.fpml scaffolded; export/import postponed. |
||
| Compute grid analysis (BOINC-based) | BACKLOG | design pass; implementation deferred. |
Tooling
| Story | State | Start | End | Description |
|---|---|---|---|---|
| Codegen infrastructure | DONE | 2026-01-24 | simple in-tree codegen; domain-types SQL; ER diagram from SQL. | |
| SQL directory refactor | DONE | 2026-01-24 | create/, drop/, populate/ by component; safer teardown; admin naming convention. |
Documentation
| Story | State | Start | End | Description |
|---|---|---|---|---|
| External data reorganisation | DONE | 2026-01-24 | domain-specific subdirectories + manifests; coding schemes via DQ pipeline. |
Agile
| Story | State | Start | End | Description |
|---|---|---|---|---|
| Sprint 10 housekeeping | DONE | 2026-01-27 | backlog + OCR + misspell-CI fix. |
Charts
Charts generated via sprint_charts cmake target.
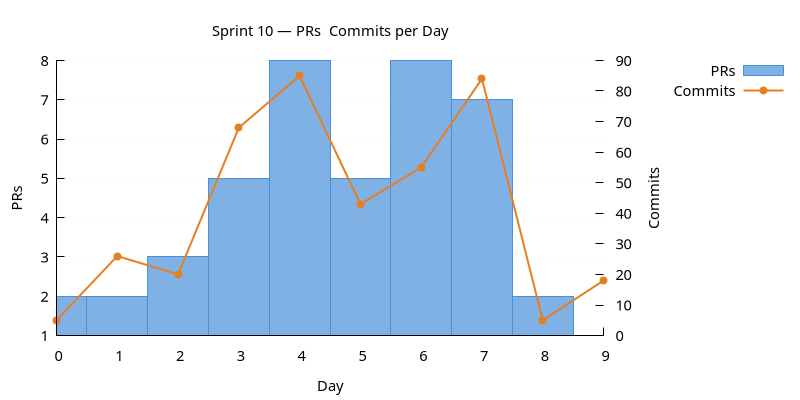
PRs & Commits per Day
Dual-axis bar chart. PRs (left axis) and commits (right axis) per day. A high commits-to-PR ratio may indicate scope creep.
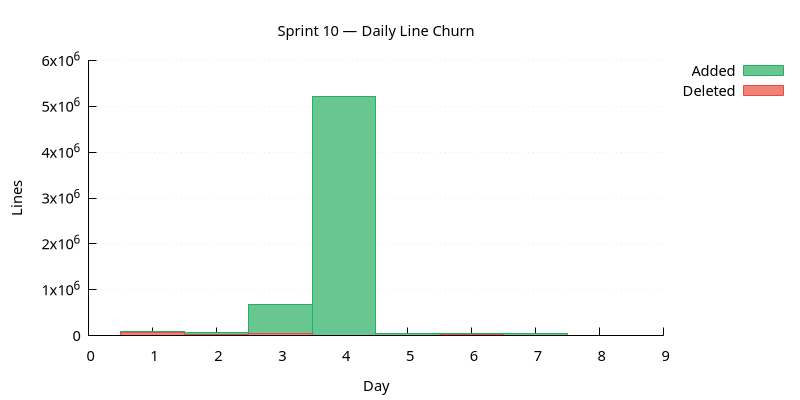
Daily Line Churn
Lines added (green) and deleted (red) per day. Building work produces mostly additions; refactoring produces a mix. Days with no churn may indicate blockers.
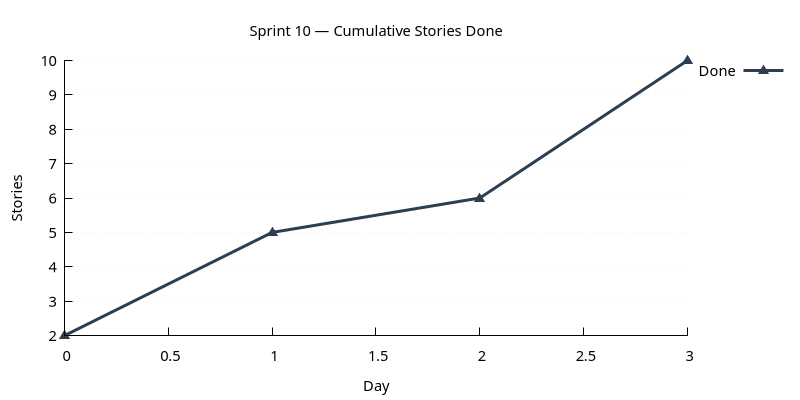
Cumulative Stories Done
Line chart tracking stories marked DONE during the sprint. Steady upward slope is healthy; plateauing signals a stall.
Retrospective
What went well
- The codegen-first approach paid back immediately: domain-types SQL, ER diagram, party reference data (13 entity types in one PR) all landed cleanly thanks to the new infra.
- xsdcpp got us from manually writing ORE types to real ORE samples round-trip through generated code inside a single sprint, including the upstream issue + the Windows MSVC follow-up.
- The metadata/production schema split was the right shape for the bootstrap wizard — the wizard could be much simpler than it would have been before the split.
- Three SQL-directory refactor PRs landed back-to-back without breaking the world, thanks to git-history-preserving moves.
What hurt
- The PR for party-related schemes was huge (15 entity types, 18 datasets). It landed but the review surface was unfriendly.
- Claude Code token budget was the precipitating cause of the codegen story — felt like a forced move rather than a deliberate investment. Still worth doing; just worth noting.
- The misspell-action fix was annoying out of proportion to its size — GLM 4.7 kept suggesting unhelpful approaches before manual fix-up.
- xsdcpp gaps surfaced late (sub-elements / substitution groups);
documented in
ore_xsd_schema_gaps.mdrather than fixed in-sprint.
What changed
- Codegen is now a load-bearing part of the workflow, not a one-off.
ores.oreis the new home for ORE-specific import/export.ores.fpmlis scaffolded for the FPML side, even though its implementation carries forward.- Database schema is split into
metadataandproduction; the bootstrap chicken-and-egg is resolved. - Bootstrap is a Qt wizard, not a shell ritual.